Blockchains and Scale: Part 1
Can current blockchain architectures scale securely?
Blockchains are a secure database technology suitable for fintech or other peer-to-peer interactions. This ability to interact with peers without centralized intermediaries offers a unique value-proposition: sovereignty.
The promise of Bitcoin is sovereign currency, free from any one government's policies. The promise of web3 blockchains is sovereign platforms: a shared, open, and interoperable cloud that anyone can build on top of.
This vision of re-decentralizing the internet is quite bold, and has given rise to the field of trust-minimized computing, with projects promising decentralized compute and storage services.
While still in its early innings, questions around product-market-fit, safety, and regulations have yet to be worked through. Besides product and market factors, a relevant question worth exploring is: what are the near-term technology bounds on decentralized architectures?
I’d argue that mainstream use-cases will be viable only if the technology behind these promises matures. Here, that means safe and secure database that can scale to billions of users and interactions in a cost-effective way.
Here, I am exploring key concepts behind this technology, with the hope that it can lead to clearer understanding and reasoning behind scale challenges. The intended audience is engineers who have a technical background but have not explored blockchain’s system architecture.
Part 1: The Blockchain
We can think of a Blockchain network as a cloud database service that stores and retrieves data, similarly to CloudSQL or AWS Redshift. You may have seen the chain-of-blocks explanation, but here I will provide a more nuanced viewpoint.
The purpose of this technology is to have a shared database not controlled by a small group of people or institutions. As with a database, it provides some degree of both storage and compute, but the key differentiator is immutability and decentralized control as its core security promise.
In part 1 we will cover the basics of a blockchain architecture, including Data model, Security, Consensus, Finality, and Economics of block creation. Part 2 will explore approaches to scale including Ethereum’s internal architectural scaling and external L2 approaches, and in Part 3 we will take deeper look into the most promising solution to scale known as ZKP or simply, cryptographic proof systems. By the end I hope the reader has enough information to make up their own mind on the path and challenges to scaling decentralized platforms.
The Datamodel
Understanding how data is stored and updated is the key to understanding how updates may scale. The two most popular blockchains, Bitcoin and Ethereum, differ on its internal datamodel choices. Bitcoin’s UTXO and Ethereum’s Account model, while differing in details, are both ways of storing and updating database state.
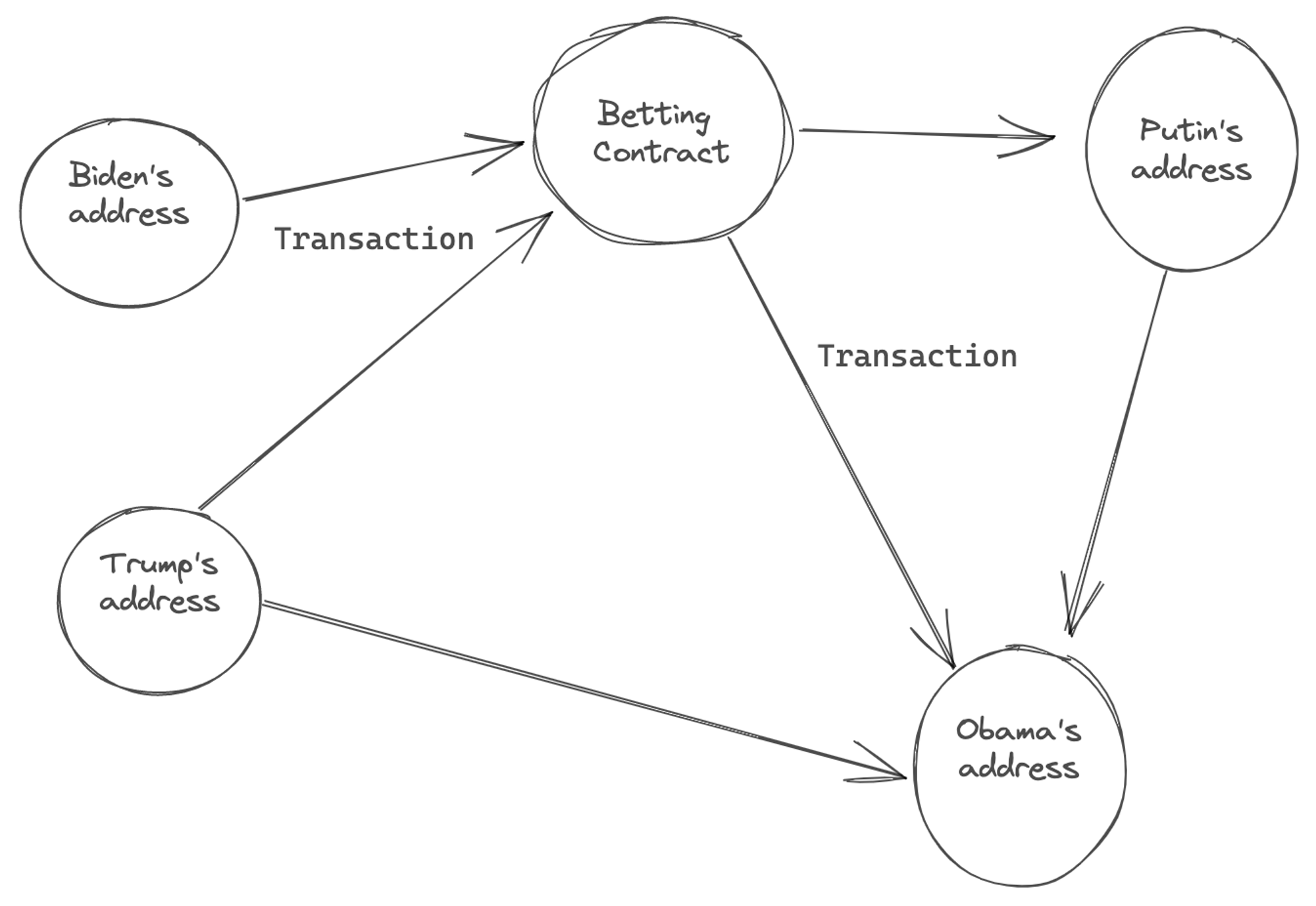
Both have a notion of {accounts} and {transactions}. Essentially, we can think of blockchain state as a graph with Accounts as nodes and transactions as edges that change the state within one or more nodes.
UTXO
The UTXO model adopted by Bitcoin maintains a global registry of transactions. Each transaction consumes and produces “boxes” of secure state (e.g. satoshi values) that can only be controlled by an account holder’s private keys. Each account has many such boxes at any time, resulting from previous transactions. Think of it as your spare change scattered around in many places.
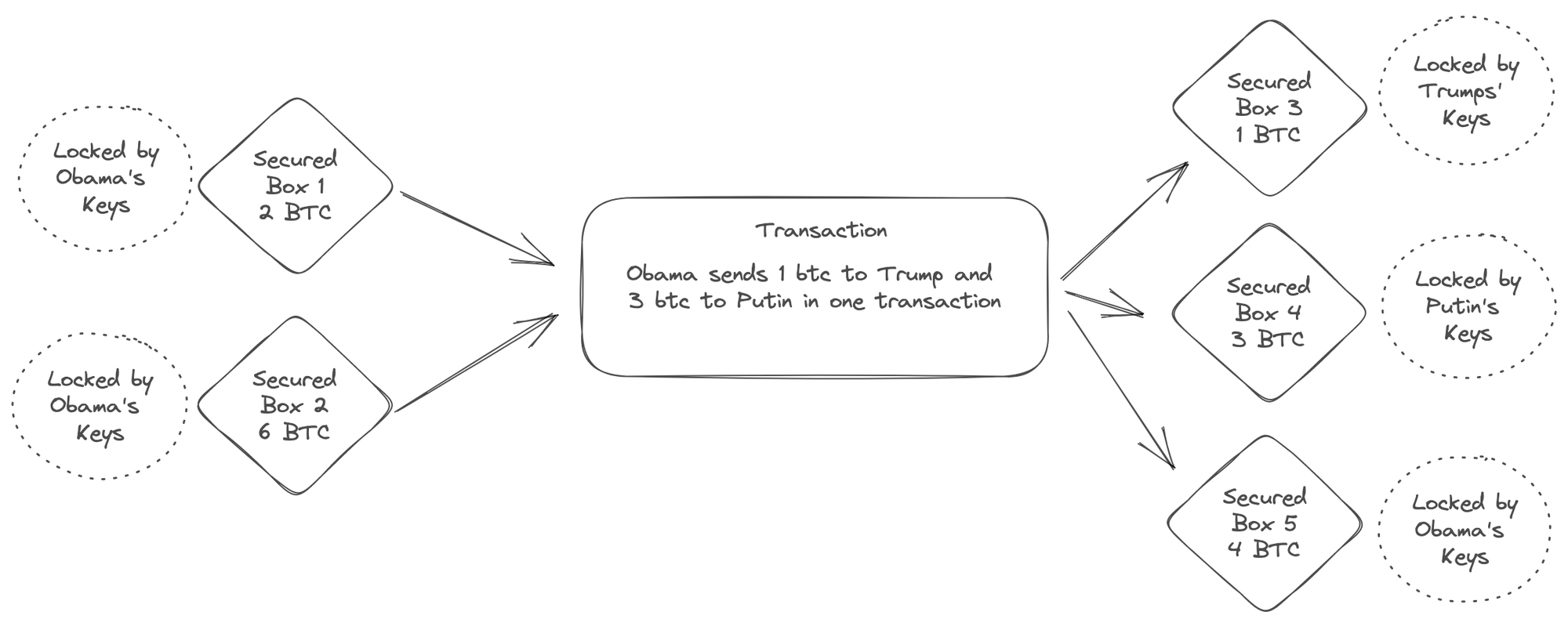
One of the big advantages of UTXO model is that it is better suited to scale as it allows for parallel processing across multiple addresses. Transactions that refer to independent inputs can be processed in parallel. Although, there are also downsides with not having all of account information in one place.
Account Based Model
The UTXO model is less extensible when securing arbitrary state through a transactions, such as smart contract data.
Ethereum chose the data model where each account stores and secures its own state - similar to your bank account. There are two types of accounts: Externally Owned Accounts (EOA), which is what we deal with in wallets, and Smart Contract accounts - both have their own nodes in the graph.
As an aside, Ethereum’s major push for Account Abstraction (Smart Contract based Accounts) is shifting the system away from pure EOA so that users can embed logic and safety into managing their ethereum access. Nevertheless, the ideas here still apply in its entirety.
Each node stores state around current Ethereum (eth denominated) balances, arbitrary storage, and code-space. If the recipient's account has code, a transaction runs it, potentially changing internal storage or creating additional internal transactions that have subsequent effects on debits and credits to other accounts.
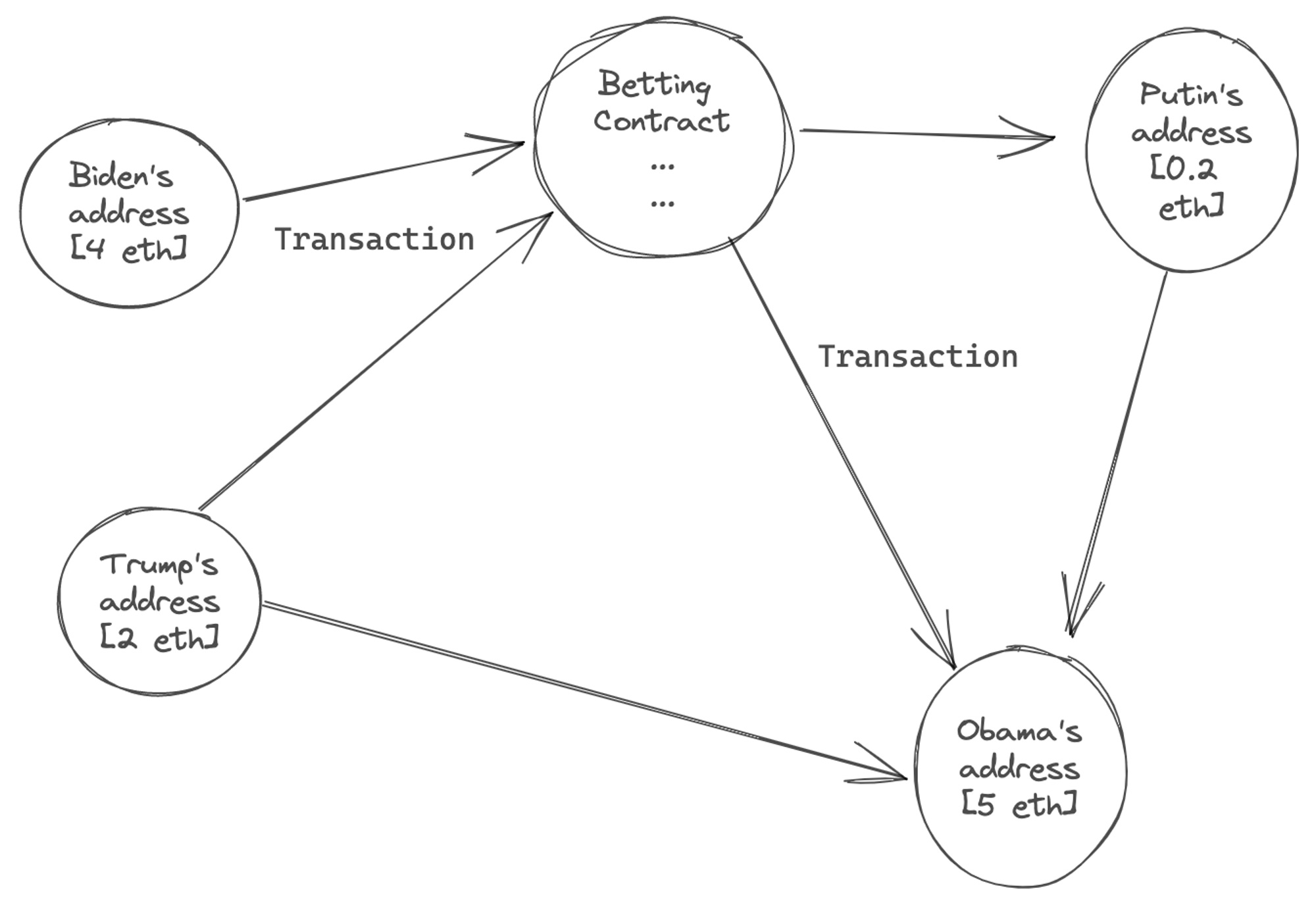
In this model we view state of the Ethereum database as a NxN graph.
It is this clique property of the graph that makes blockchains state update hard to partition, and therefore hard to scale. In a block state-change any account could change state of any other account, and all of this has to be validated by the validator nodes to make sure no one is double-spending, or more generally, making invalid state transitions. More on scale challenges later.
Smart Contracts
Ethereum supports smart contracts whereas Bitcoin as a principal doesn’t. Smart contracts are arbitrary programs that are executed in a sandboxed environment on node, and whose output is to change Balance or Data fields for itself or another user address. Smart contracts are programs that user can upload to the network. Maybe they should just be called programs or apps.

Within Bitcoin protocol a transaction’s execution is well-defined into the protocol and is generally limited to moving bitcoin balances around. Whereas in Ethereum, a transaction may execute arbitrary logic before the transaction output is decided, which may even be updates to just data and not balances.
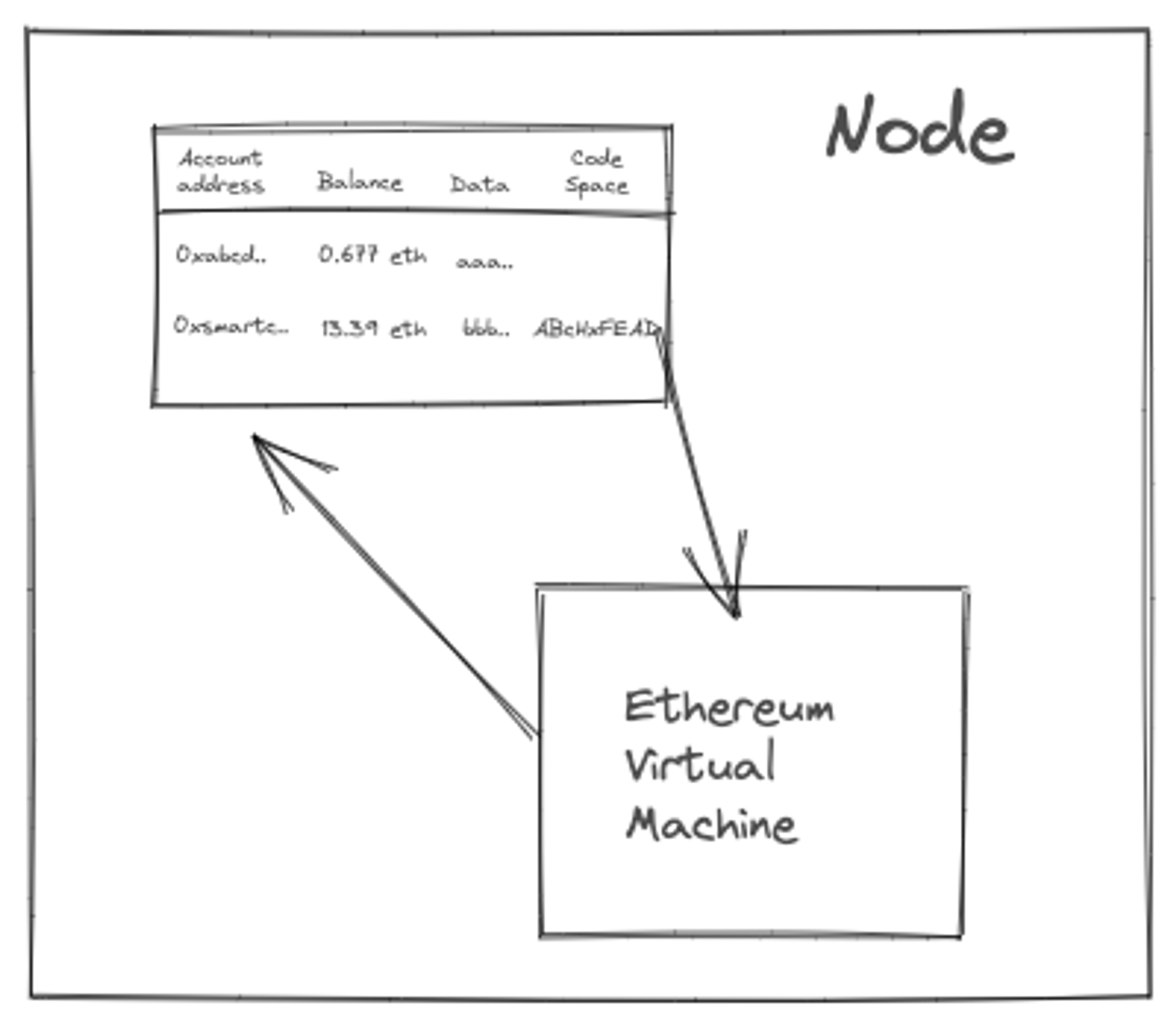
A virtual machine executing the program simply executes a set of instructions called OPCODEs. If you have ever looked at assembly programming then this should seem familiar.
The Bitcoin community felt that introducing programmability to the network will create challenges with decentralization, scalability, and hinder adoption of money transfer usecase. Besides these, there are clear challenges and limitations with having arbitrary logic run on the blockchain nodes:
- It increases storage requirement on the nodes. The smart contract program as well as data take up space, and while there are financial costs associated with it, it does impede scale as all nodes are required to store all smart contracts ever created in its local storage.
- It increases compute requirement and adds more pressure to the redundant computation nature of arriving at consensus.
- While they are arbitrary programs, they do run in a Virtual Machine as defined in Ethereum spec (it cant’ access hardware resources for example), and its output have to be brought to consensus across network nodes. This forces smart contracts to be deterministic so that every node running it will get the same result, and prevents any interactions with API or information outside of blockchain network. For example, it can not make a http call or access machine’s local storage.
We can think of Ethereum as a decentralized database with macros. I still view this a database and not general purpose compute since the entire purpose of smart contracts is to update the database state. Macros were introduced in relational databases to bridge the datamodels between relational system and programming layer, and it is the same here.
Tokens
All blockchains have a native token / currency. The balance field of the data model is denominated in its native currency. The currency has different denominations, for example bitcoin has sats and Ethereum has wei, which as smaller units.
A Token is a concept that arose from smart contract programming. Smart contracts allow users to program their own currencies and encode economic primitives like units available, inflation, ownership, etc. Interestingly, an app may also allow its owners to change the code, posing some threats to users.
Tokens are represented in code as an Array, or a Map. Thats it!
Fungible tokens, like a currency simply map owners to the amount. The total across all owners would have to add up to a predetermined value. NFTs map owner to one of the token ids. All of this data lives in the data field of the smart contract state, and is updated by smart contract execution.
Note that there are validity rules with data updates that ensure a state transition is only considered valid if the address updating it has the right permissions. This, among other validity rules, is also why a takeover by dishonest super majority will halt the network, but never steal your funds. People will simply not trust a network that is outputting invalid state transitions, and rebuild the state from even a single node with valid chain of states.
Recap:
So far we see blockchains as a network of peer-to-peer nodes (machines), each carrying an internal state of the the network graph (database), and communicating with each other through a protocol (language). Bitcoin is a protocol. So is ethereum. So is http that you use to access the web, and so is your email access through smtp/pop. A client like Chrome, outlook, or gmail honors that protocol. In Blockchains, since financial value is at stake, any node on the network that doesn’t follow the protocol rules are penalized and even banned by rest of the “honest” nodes.
Security through Decentralization and Consensus
We covered what the data-model of a decentralized DB looks like. Now let’s think about how it can provide security guarantees. We’re talking about a specific set of guarantees, namely:
a) decentralized control - a high amount or percentage of resources of the distributed network an entity would have to acquire to seize control over the network (including its runtime state, history, or changes to code)
b) immutability - no one unauthorized can change the state or history in a way that other nodes agree to that change
Every distributed system has a consensus algorithm. Consensus is a process by which distributed agents agree upon a decision. Distributed database systems have consensus protocols like two-phase and three-phase commit sequences. These have been studied in the context of properties such as Agreement, Validity, and Termination.
On top of being a distributed system, Blockchains are “decentralized” architectures, meaning a validator node does not trust any other node in the network. Each validator, who is honest and follows protocol rules, can derive its confidence on state of the blockchain data by observing their peer validators in the network. Moreover, each dishonest validator has financial disincentive to be dishonest. These types of distributed computing environment are called Byzantine environments after the field of Byzantine Fault Tolerance problems.
Consensus
What is consensus? It is a commitment scheme. It is a set of rules by which a node (or an agent, or user) achieves confidence that a specific view of the world (chain state) is the true one, and they should build transactions on top of the consensus state (i.e. commit it).
Byzantine protocols have been studied in distributed systems and model algorithms for making collective decisions in a distributed fashion when unknown number of peers have been compromised. Blockchain protocol follow a byzantine consensus algorithm such as pBFT, Nakamoto consensus, or its variation. The byzantine property of blockchains means you can’t use classical 2-phase/3-phase commits and have to rely on probabilistic commitment schemes.
Practical BFT and Delegated BFT are permissioned leader based protocols that work upto 33% of Bizantine faults (dishonest nodes). The nakamoto consensus algorithm is a beautifully simple innovation that solved these limitations for a permission-less blockchain environment and also raised byzantine fault boundary to 50%. In his (or her) seminal paper, Nakamoto devised it as following the most difficult chain. The longest chain (from multiple proposed branches) represents the most work done by the network. Following a chain constitutes a vote and requires no back-and-forth communication.
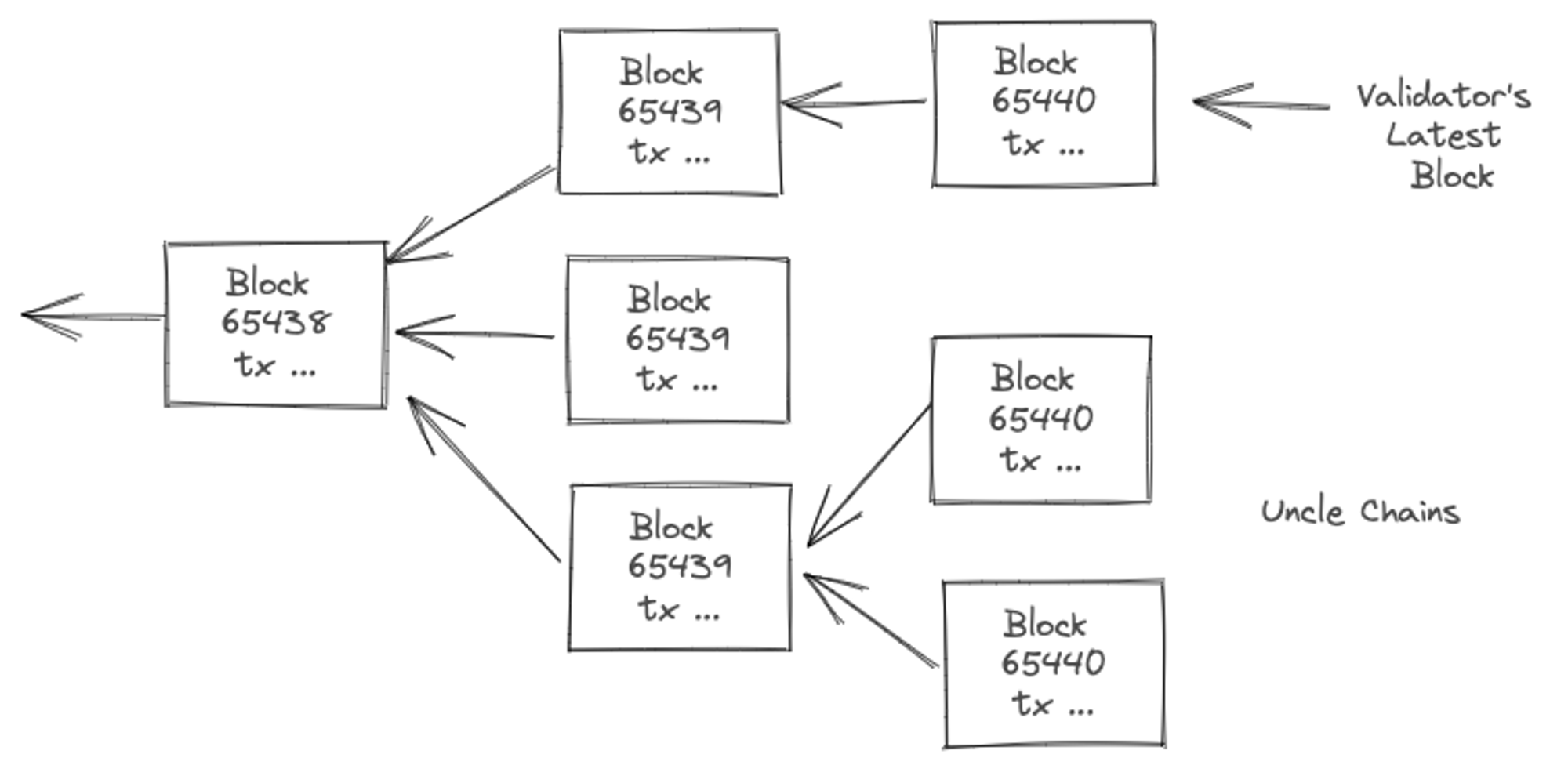
However, the protocol only provides probabilistic guarantees on finality that increases with time. The downside is that users have to wait for a few blocks being built on top before being confident that their transaction was committed. As you’ll see a bit later, as a result of nakamoto consensus, a node may end up following a branch that does not reach consensus and its internal state may have to be re-orged to stay compliant for its peers. Typically, a blockchain client will maintain multiple recent branches in case it needs to reorg.
There may be entry-ticket and associating penalties for participating in a consensus round. These are typically Proof-of-work, Proof-of-Stake, or Delegated-Proof-of-Stake models. PoW involves computing a complex hash sequence in order to elect which miner’s block is the one the network shall follow, whereas PoS wages a stake to participate in the round after which a random weighted draw elects the validator for that round. More details on Ethereum’s Casper and Ghost proof of stake algorithms are in the paper.
But what all this means is that a state update to the database, through block formation, has to be performed by all validators and reach a consensus.
I just want to update a row in a database and I have to run 1000s of redundant computations? Yes - thats the cost of decentralized security.
This consensus state is probabilistic and not all nodes will agree 100% on the final state at the time of block commit, and there is a chance your node could have agreed on a non-final block. (read block as state-change to the database)
As an aside, note that if you are a honest node, you will only accept valid state-transitions. i.e. you won’t spend balances an account does not have. However, you may have agreed upon a valid block (state change) for current block formation, but rest of the network can eventually agree upon another valid state change for the same block formation, rendering your state non-consensus.
If this happens in a significant number of nodes, it partitions the consensus chain, often called uncle chains. Once a chain partition loses the majority, it needs to be reorged else it is out of the game as no one will follow non-consensus chains. You can think of a node following a chain path as a vote given to what it think is the consensus state branch.
There are few reasons for not reaching 100% agreement. Here the exact details vary based on the specific blockchain (Bitcoin, Ethereum, Solana), but I will explain common reasons at a high-level.
- Malicious node - set of nodes intentionally making invalid state transitions will cause honest nodes to disagree with them
- Distributed network - different validator/executor nodes add different transactions to the block (there are nuances that differ on PoW, PoS, or PoH model)
- Network latency and communication - causing network partitioning, and related to (2) above.
- Client-side bugs - different validator client code have bugs or implementation differences.
Finality
Hence, the concept of finality arises, and an important one to internalize when comparing blockchain solutions. In Bitcoin, for example, it is highly unlikely that your transaction will be undone and re-orged, when several other blocks have been chained on top of your block.
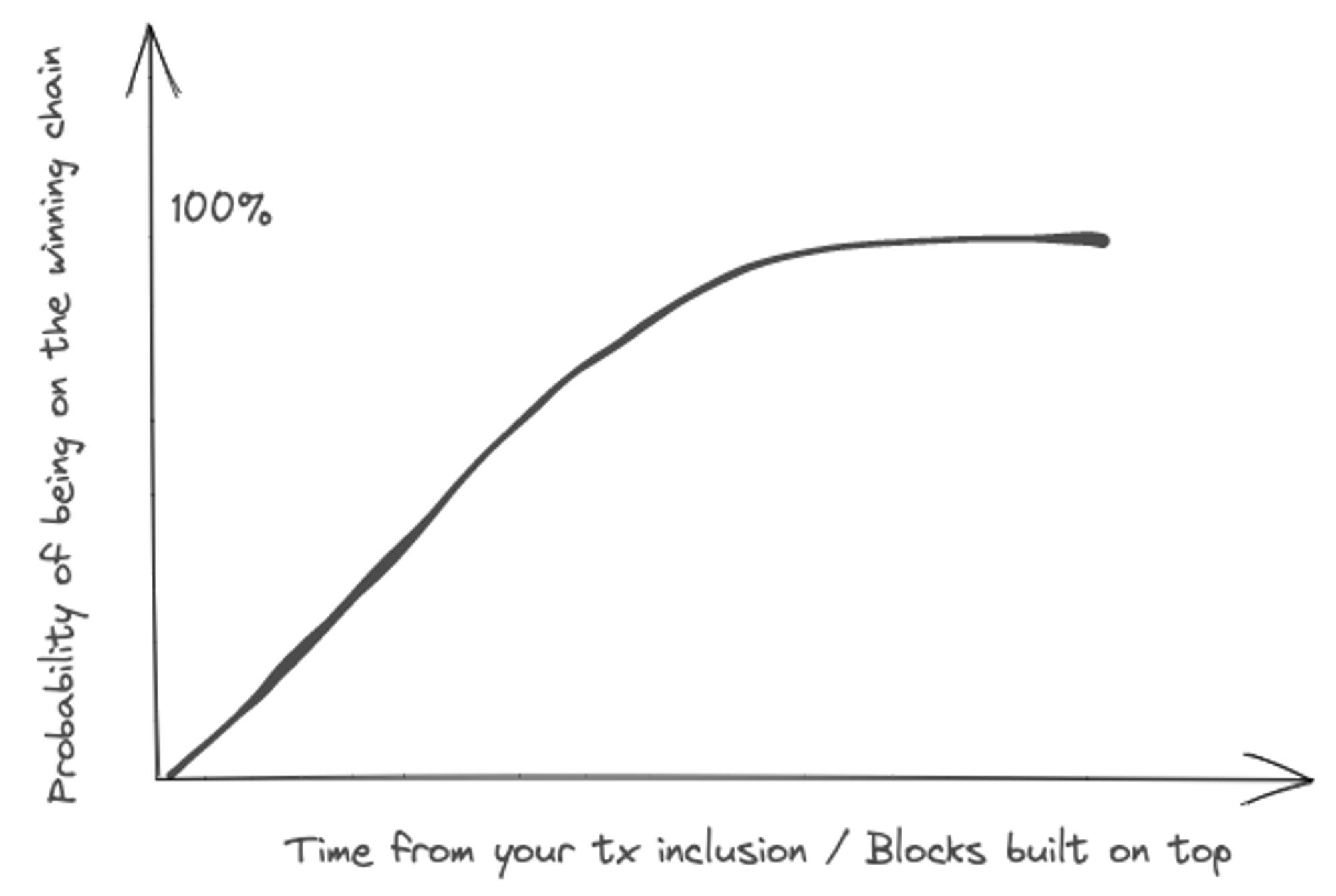
When can you be reasonably confident an addition to the blockchain database has taken place?
Every blockchain protocol’s architectural choices provides different finality timeframes. Here is an overview of time-to-finality that some people feel comfortable with:
| Time to Finality | ||
|---|---|---|
| Bitcoin | 60 mins (6 confirmations) | |
| Ethereum | 78 secs (6 confirmations) | |
| Solana | 2-46 secs | |
| L2 Optimistic Rollups | 7 days (fraud proof window) |
Back to consensus and immutability.
So, a blockchain network is a set of validator nodes who try to agree on the state-changes over time by following a consensus algorithm. Each validator only trusts itself and no other peers, carrying a full state of the database in its storage. They communicate with each other through a common language (the specific blockchain protocol), and can tell who speaks their dialect and who doesn’t - i.e. which validator is not following the protocol.
Data Growth: It is impractical for a node to store all of the historical state-changes. The Ethereum protocol is evolving rapidly and accounts for storing partial state and that too over recent time interval only. More on this later as it impacts scaling.
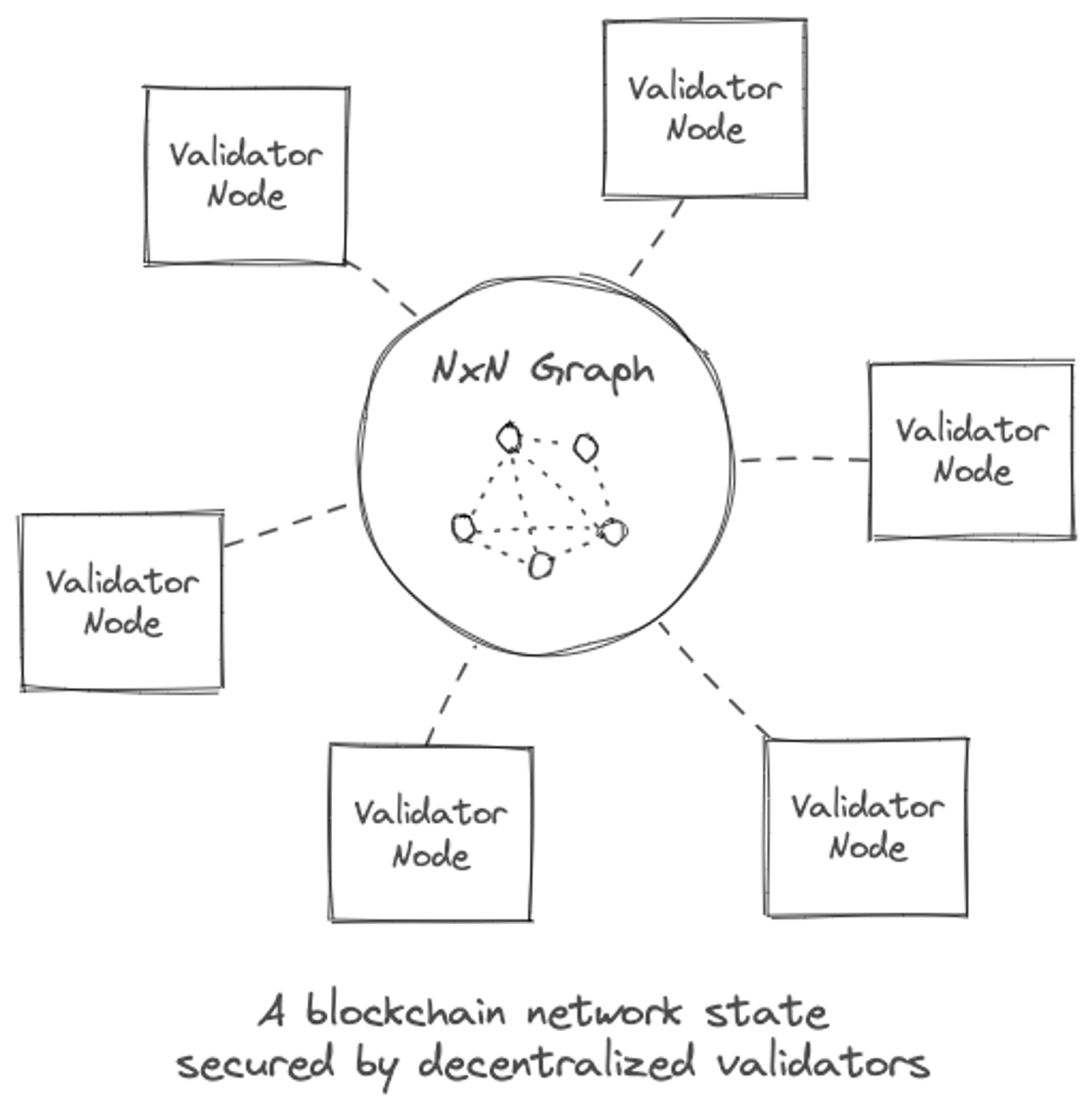
Immutability
Its immutability property comes form the fact that state-changes over time, i.e. the block-formation, builds upon the previous state. A good analogy is reverse linked-list - a chain of blocks, and this is where it gets its name Blockchain.

One option is to query multiple independent nodes and compare. For example, I could query multiple nodes for who owns a specific NFT, or what were the last 10 transactions of a given address, and compare the output. This is not efficient.
Another approach is to replay all of blockchain transactions, forming and validating each block from a prior trusted checkpoint until you can validate your intended transactions. This approach is also not very efficient.
The only viable trust-worthy approach is to validate relevant data yourself through a light-client. A blockchain light client queries a (trusted) full client, and partially replays block-headers to ensure each block is in a valid state. You can then probe its merkle-tree (set-membership test) to mathematically validate that a transaction was included in a given block.
While not straight forward, one can imagine a light client embedded with a browser, approving your interactions with blockchains, similar to how SLL certificates are validated in the browser.
Nevertheless, at larger scale, the question of "trust" remains open when you don't run the node yourself.
Uncle Chains
Being a decentralized protocol, there are conditions under which different validator nodes build and agree on different set of transactions to be included in a block. Due to the probabilistic nature of consensus algorithm this alternate view could end up being the majority view, and therefore the main chain path. To account for this and re-organize its view in the future, a validator needs to keep track of multiple possible block instances within last few blocks formations. These uncle blocks are more prevalent when mined blocks propagate slowly within the time gap between block formations.
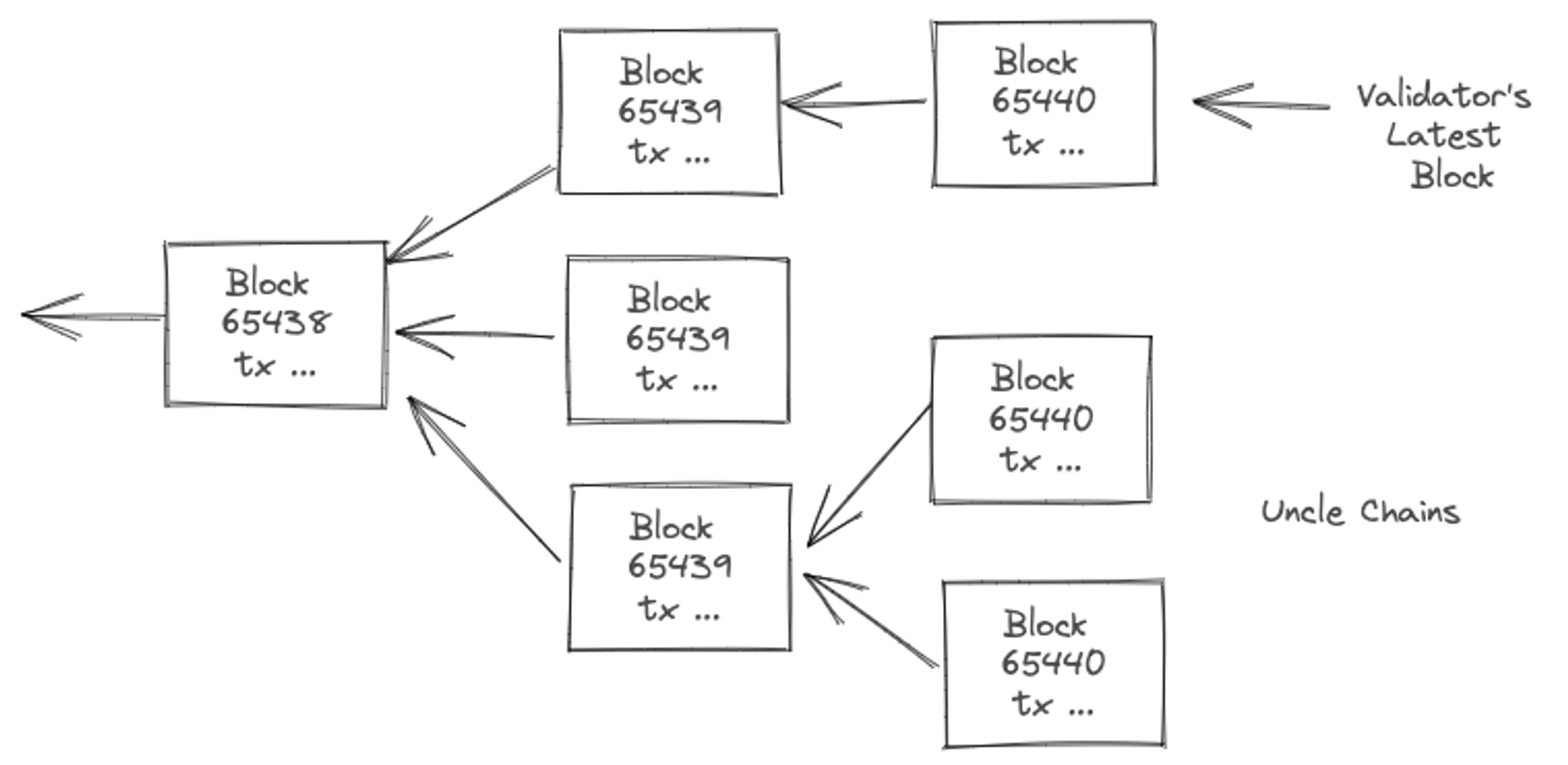
Shorter the block-formation time, more uncle blocks arise.
A block is like a train leaving a station on a precise and predetermined cadence. It has fixed room for a maximum number of passengers (transactions) in every departure. When more passengers (transactions) want to be included, the entry fee (gas fee) goes up.
This is where the train analogy breaks down, but I shall try nevertheless. There is a queue of passenger waiting for a seat (transaction mempool. However, every ticket counter (validator/miner) has their own view of mempool, or their own queue, depending on how far the transaction request has propagated through the network. Moreover, each validator / miner has their own view and incentives for including transactions in the block. Continuing with the now horribly broken analogy, each ticket counter will try to fill a train with different combination of passengers. One (or few) of them will win the lottery and be selected as the winning combination to fill the train.
Interestingly, including or excluding transactions in a block can be profitable for a miner himself! Besides the mining rewards, this is a lucrative way for miners to profit and compete on block formation. An entire area has arisen pertaining to exploiting these mining rewards, called Maximum Extractable Value (MEV).
Incentives
The blockchain protocol defines certain incentives and disincentives for behavior. I will not go into the details as it is less relevant to scaling and more interesting for economic design. At a high level Ethereum’s incentive model covers:
- User’s transaction fees (gas fees) for writing to the network since consensus is required.
How gas fees are calculated is somewhat involved but is a proxy for costs of compute and storage that the validator nodes may incur, and is a function of opcodes, transaction, and data needed to store on the node. - All write operations on a network is a transaction and incurs gas cost, including uploading or changing a smart contract!
- Reading data is free as it can be read from a single node.
- Miner or validators rewards for executing and securing the network. The network protocol codifies how much reward to pass on the the miners, and depending on the consensus algorithm the details differ quite a bit.
- Miner (or validator) stake for participating in the network (roughly $200k to start validating).
Staking allows creating disincentives for bad behavior: such as being unavailable on the network, and executing dishonest transactions (that consensus of network deems invalid)
The Mempool and MEV game
So far we have established how blockchain protocol, using a distributed and decentralized set of nodes, who are financially incentivized to act according to the protocol roles, provides a decentralized database abstraction. It secures the database network through a consensus protocol, trading-off time-to-consistency (finality) and financial cost of operation.
Besides block-building rewards there are other ways miners (or validators) can earn rewards and be financially incentivized to participate in the network. Some upcoming architectural changes to Ethereum protocol has given rise to a block-building optimization technique referred to as “Maximal Extractable Value” or MEV.
Ethereum network’s roadmap is to move from a monolothic architecture (validators node is responsible for everything) to a decoupled architecture, where responsibilities for building a block, validating, etc. are split into roles.
Intuition behind MEV: Block-builders typically choose to include transactions to the block based on profitability. This usually means transactions willing to pay highest amount of gas fees. In traditional exchanges high-frequency traders exploit arbitrage opportunities, in return keep the marketplace price-efficient. Similarly, MEV allows block builders to profit by choosing order and inclusion of transactions from the mempool.
This typically involves exploiting arbitrage, front-running, or liquidation tactics and requires a blockbuilder to insert its own transactions to extract the value (only when profit offsets gas fees plus potential slippage). As you can imagine the search space can be vast and it becomes a combinatorial optimization problem with advantages favoring algorithm, compute capacity, as well as low-latency access to exchange and price data. Wow! this is looking a lot like traditional fintech technology.
Interestingly, this has created created a marketplace of specialized services — that are not part of the decentralized validator network. One could argue that harder the MEV profit extraction becomes, the more reliance on centralized providers to run an effective network.
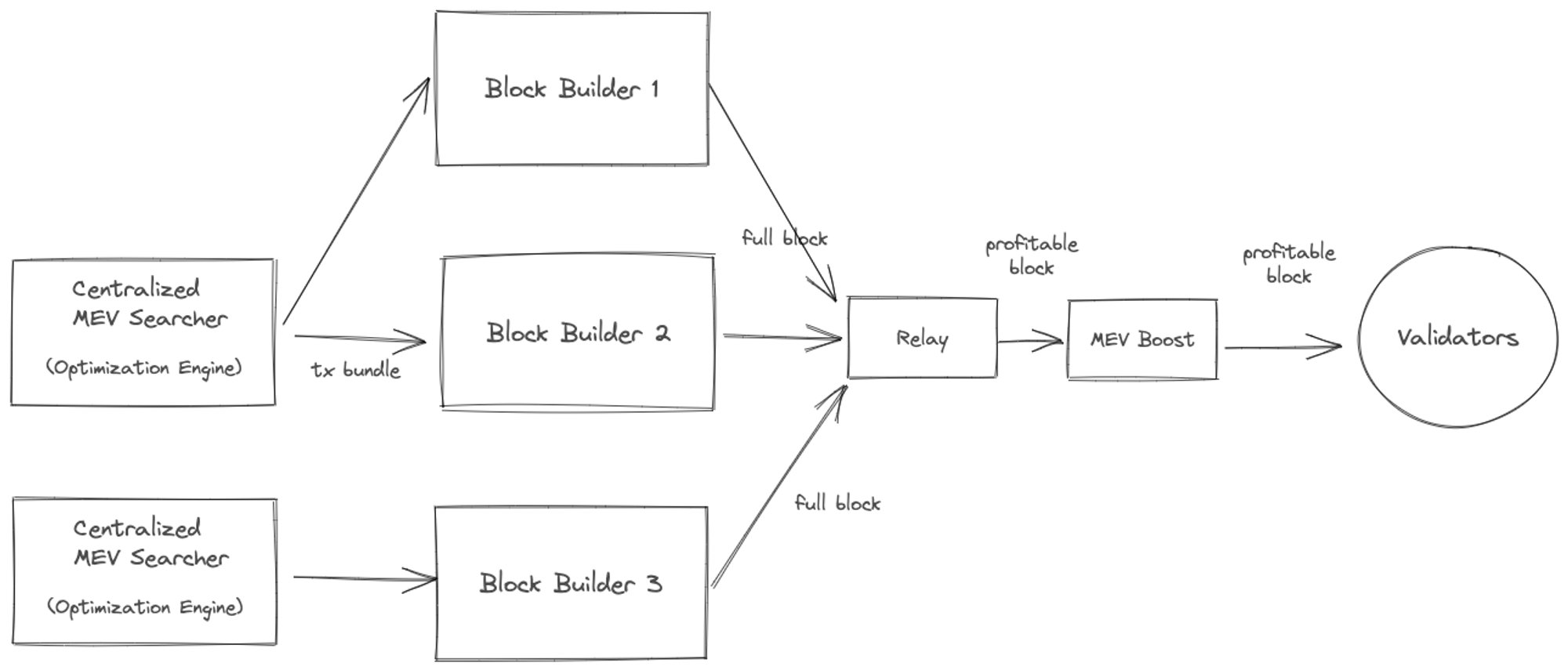
The full depth of MEV ecosystem is beyond the scope of this post and deserves a deep analysis of its own. The key take-way is that there is a deep ecosystem of arbitragers who keep the marketplace somewhat stable and scaling strategies that that the chain adopts will have some impact on the MEV ecosystem. Additionally, decoupling of roles (execution client, validator client, shards, etc) is necessary to increase network throughput and start bringing gas prices down, but also complicates the financial incentive models.
$$$
One thing to think about is why would users pay tens of dollars to upload a program or write a database entry, when modern cloud providers like AWS, Azure, or GCP do the same for fraction of a cent?
While this has yet to play out, the reasoning resolves around usecases where decentralized security property overcomes the cost. For example, in order to deal with privacy compliance across numerous countries, the transaction cost may be irrelevant against building compliance infrastructure for a high gross-margin business.
Why are the gas costs so high in the first place?
The complexity of an update determines how much gas it will take to execute the transaction. The cost of gas fluctuates in an open market and is determined by demand/supply.
There are limited slots in a block and there are limited blocks that get confirmed per time unit. With block supply limited, each validator wants a small but profitable reward to participate. Multiply this cost by 1000s of times as consensus is a redundant computation, and we have a relatively high baseline cost of gas. Any increase on top of the baseline cost is pure demand pulling the price up.
Scaling
Security benefits in the use-cases needs to offset the high cost of redundant and slow compute incurring global network latencies. Scaling blockchains to mass-market use-cases requires:
1. Scaling network throughput
2. Reducing latencies (time to transaction finalization)
3. Reducing financial cost for each update
while maintaining the benefits and security of the decentralized network.
Scaling on all dimensions is extremely challenging with the technology we have today, and most scaling solutions today compromise on one or the other.
With this background in place, in the next part we will explore the landscape of scaling solutions that may (or may not) help increase throughout and reduce price.