Coding Assistant AI across large codebases
I was surprised to find that Github Copilot still doesn't support answering questions over your entire codebase through @workspace /explain command. This feature seems to be part of their roadmap. It got me thinking what the real challenges are behind scaling reasoning across entire codebase given that they already have a code-generation model.
Given that many codebases are large, dynamically changing, and contains numerous libraries, this would be modeled as RAG - Retrieval and Generation steps.
The key challenge is to have context Retriever pull-out relevant context.
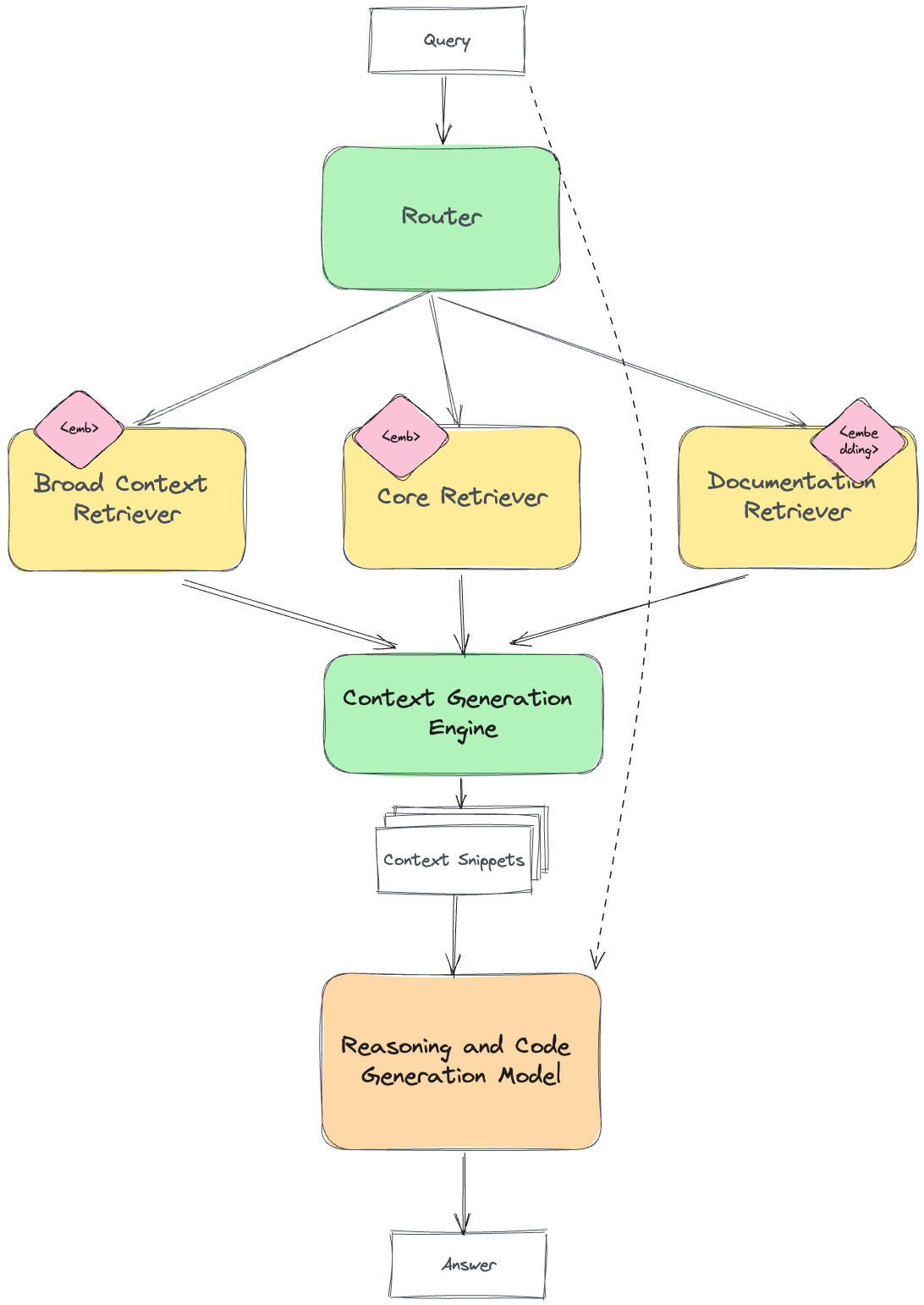
However, this is not always possible on broad-context questions such as: "Summarize the codebase, file structure, and key abstractions used". In this case, it would be reasonable to have different "retrievers", effectively built with different inductive-biases, and having a trained-router that picks the right retriever for the query.
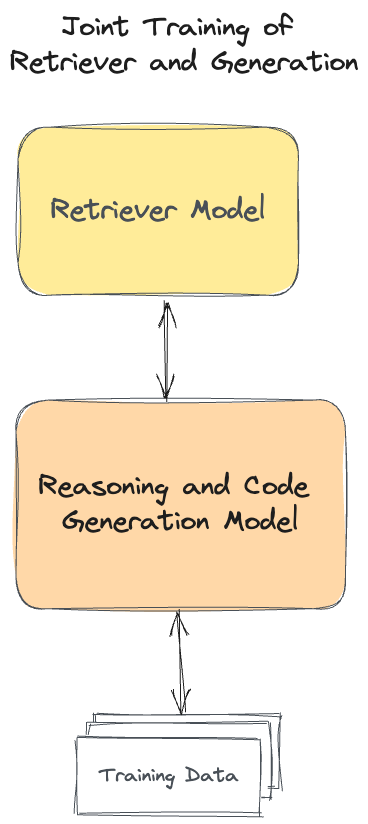
The Retriever
A precompiled index that allows quickly looking up context relevant to a given query. The context could be files, objects, or more commonly code-snippets.
- Embedding Code Snippets: Transforming code snippets into numeric vectors (embeddings) that capture their semantic and structural properties. Approaches like using a code generation model's internal state or training dedicated embedding models (e.g. REALM, CodeBERT) can be used.
- Indexing Embeddings: Building a fast k-nearest neighbor index (e.g. using FAISS, SPANN, ScaNN) on the code snippet embeddings. This allows efficient retrieval of the most relevant snippets.
- Integrating with Code Generation: The Retriever can be integrated with the code generation model in various ways. One approach is to include the retrieved snippets directly in the prompt sent to the code generation model, as seen in REALM. Another method, used by kNN-LM and RETRO, is to affect the probabilities of the generated text based on how the retrieved snippets continue.
Challenges
- Architecture: Where should the index be stored and processed? Client-side or server-side? This involves balancing latency, computational requirements, and security/privacy concerns.
- Embedding Quality: Choosing the right embedding model and training approach to balance speed and relevance of retrieved snippets. Evaluating embeddings in isolation, without live user testing jointly with reasoning model is also challenging.
- Latency vs. Quality: There is a fundamental tradeoff between the speed of retrieval and the quality/relevance of the retrieved snippets. Striking the right balance is crucial for a seamless user experience.
- Scalability: As the codebase grows, the indexing and retrieval mechanisms must scale gracefully while keeping the index fresh and performant.
- Personalization: Adapting the Retriever to individual user's coding styles and preferences can further improve the usefulness of suggestions. This come naturally if the Retrieval model is trained alongside Reasoning model and the dataset contains user-specific features.
A risk with personalization is data-leakage, and ample care needs to be taken to make sure customer's private codebase information can not be trained-on and accessed by another customer.