From PPO to GRPO
2025 marked a maturation of LLM tech. The breakthrough wasn't just more data; it was a fundamental shift in how we use Reinforcement Learning (RL) to train models to reason.
Here is the breakdown of how we moved from the complexity of PPO to the streamlined efficiency of GRPO.
LLMs as Sequential Decision Makers
To understand RL in the context of LLMs, we have to stop viewing them as mere text predictors and start viewing them as agents. In this framework, an LLM operates as a policy (πθ) navigating a Markov Decision Process (MDP):
- State (s_t): The prompt plus all tokens generated so far.
- Action (a_t): The specific token the model chooses to predict next.
- Reward (R): A signal (often binary) telling the model if the final answer was correct.
The reason this "objective-driven" approach is so powerful, especially for coding, math, and logic, is that we can move beyond human preference and use verifiable rewards. If a model writes code, we can run it; if it solves a math problem, we can check the answer. This allows for a massive leap in performance in reasoning tasks while reducing hallucinations.
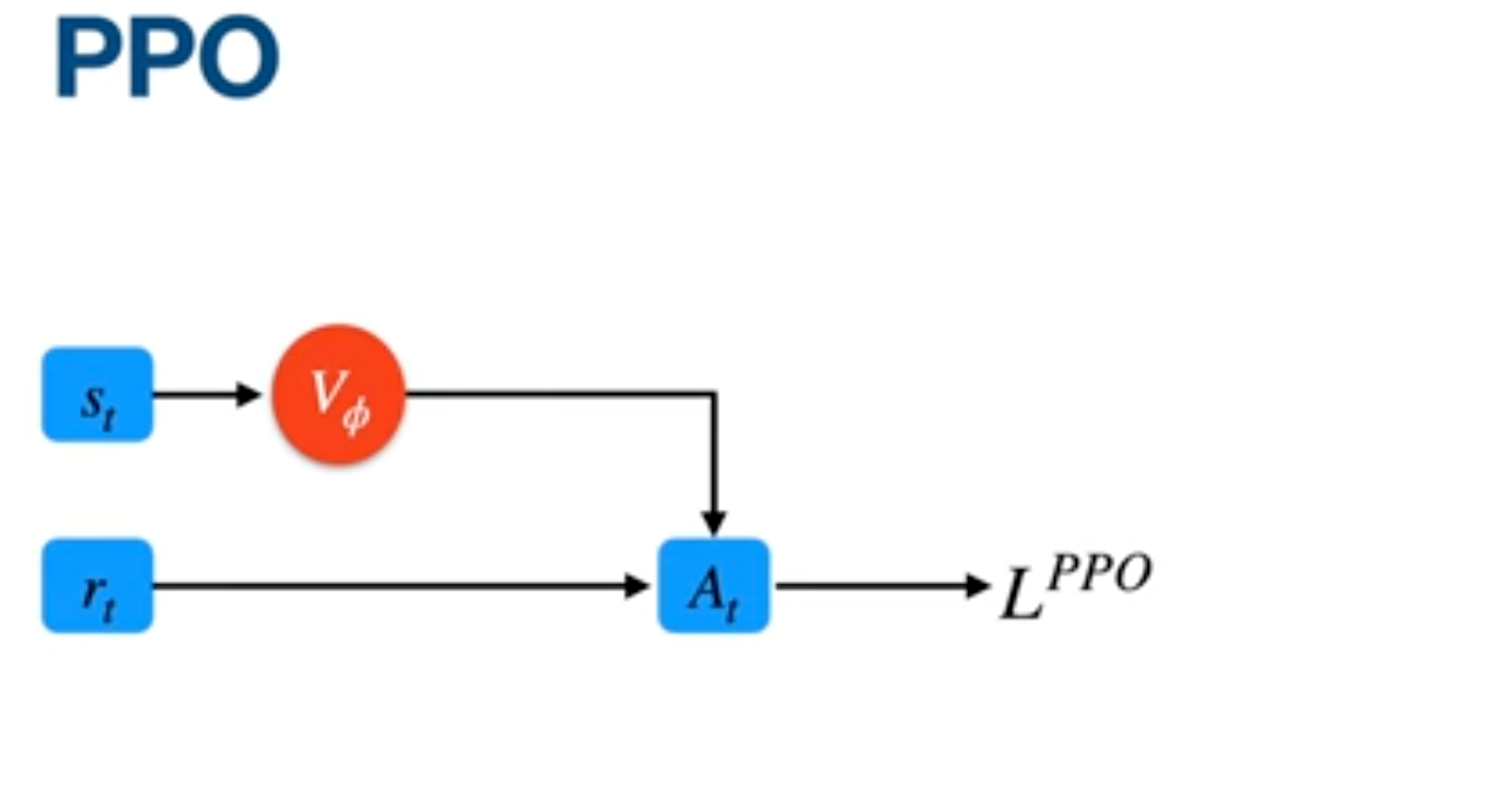
The PPO Era
Before GRPO, the standard was Proximal Policy Optimization (PPO). PPO is an actor-critic method, meaning it uses two models:
- The Actor: The LLM itself, which takes actions.
- The Critic (Value Model): A second, equally large model that estimates a Baseline for how much reward is expected from a certain state.
The Critic’s job is to lower variance. Without it, model updates are "noisy" -the model might overreact to a single correct guess or a single failure. However, building a value model for LLMs is incredibly difficult because of:
- Memory Overhead: It essentially doubles the hardware requirements since you are running two massive models simultaneously.
- Lack of Intermediate Signals: Unlike a video game where you get points constantly, LLMs often only get a reward at the very end of a long chain of thought. Intermediate reward estimations are often inaccurate (credit assignment problem)
Why PPO Clips and Regularizes
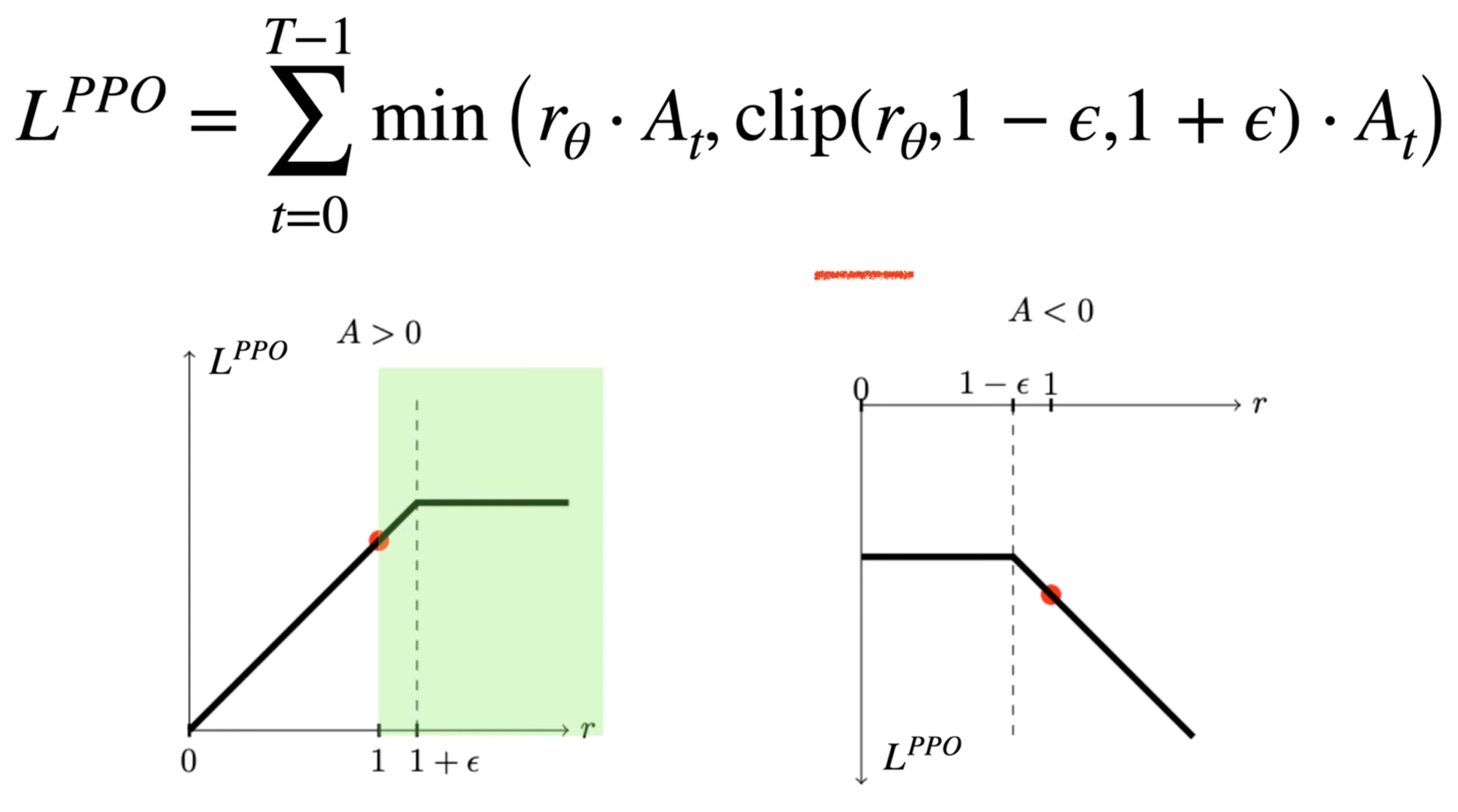
To prevent the model from collapsing or "reading too much into noisy data," PPO uses a clipping mechanism, which sort of acts as reguralization. It calculates a ratio (rθ) between the new model and the old model:
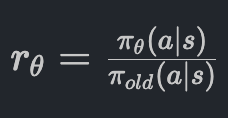
PPO then clips this ratio (usually between 0.8 and 1.2) to ensure the update doesn't move the "ball" too far off the mountain in a single step. This regularization is essential because if a probability for a specific token hits 1 too early, the model can never recover or learn alternatives.
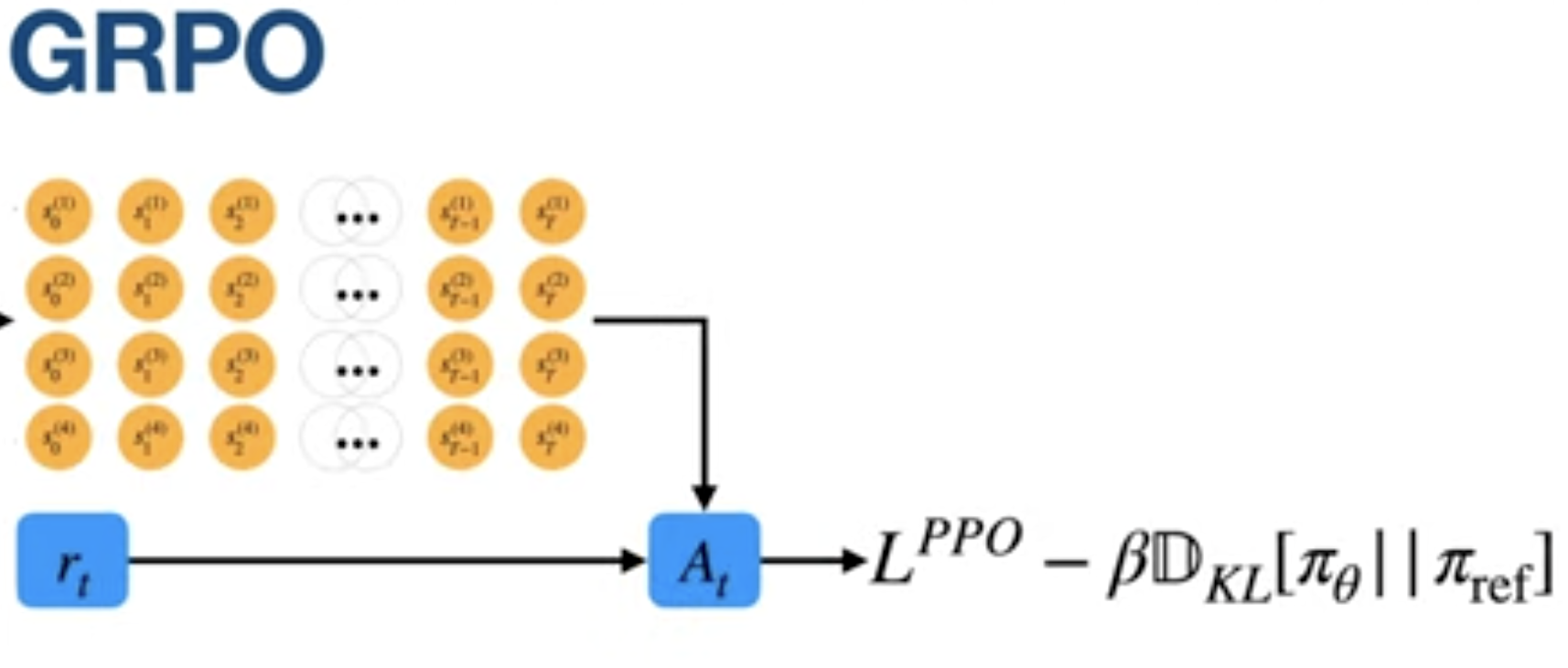
The GRPO Breakthrough: Removing the Critic
DeepSeek’s Group Relative Policy Optimization (GRPO) realized we could achieve low variance without the expensive Critic model. Instead of a separate model predicting a baseline, GRPO simply samples a group of 4 to 8 different responses to the same prompt.
The Advantage (A) which tells the model how much better a specific action was compared to average-is calculated using simple group statistics:
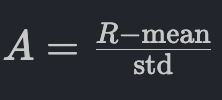
By judging an answer relative to its "peers" rather than a separate value model, researchers achieved massive breakthroughs in training efficiency. This allowed for the training of high-reasoning models at a fraction of the cost, proving that for LLMs, simplicity often beats complexity.
The GRPO loss function includes an extra KL divergence term that acts as a stabilizer between the current policy being optimized (πθ) and a reference policy (πref). While the standard PPO clipping mechanism ensures the model doesn't change too much from the previous training step, this KL term measures the "distance" to the model's state before the reasoning fine-tuning stage began - usually the model after instruction or preference fine-tuning. By penalizing large deviations from this original reference point, the model is forced to stay grounded in its foundational linguistic capabilities while it explores new reasoning trajectories.
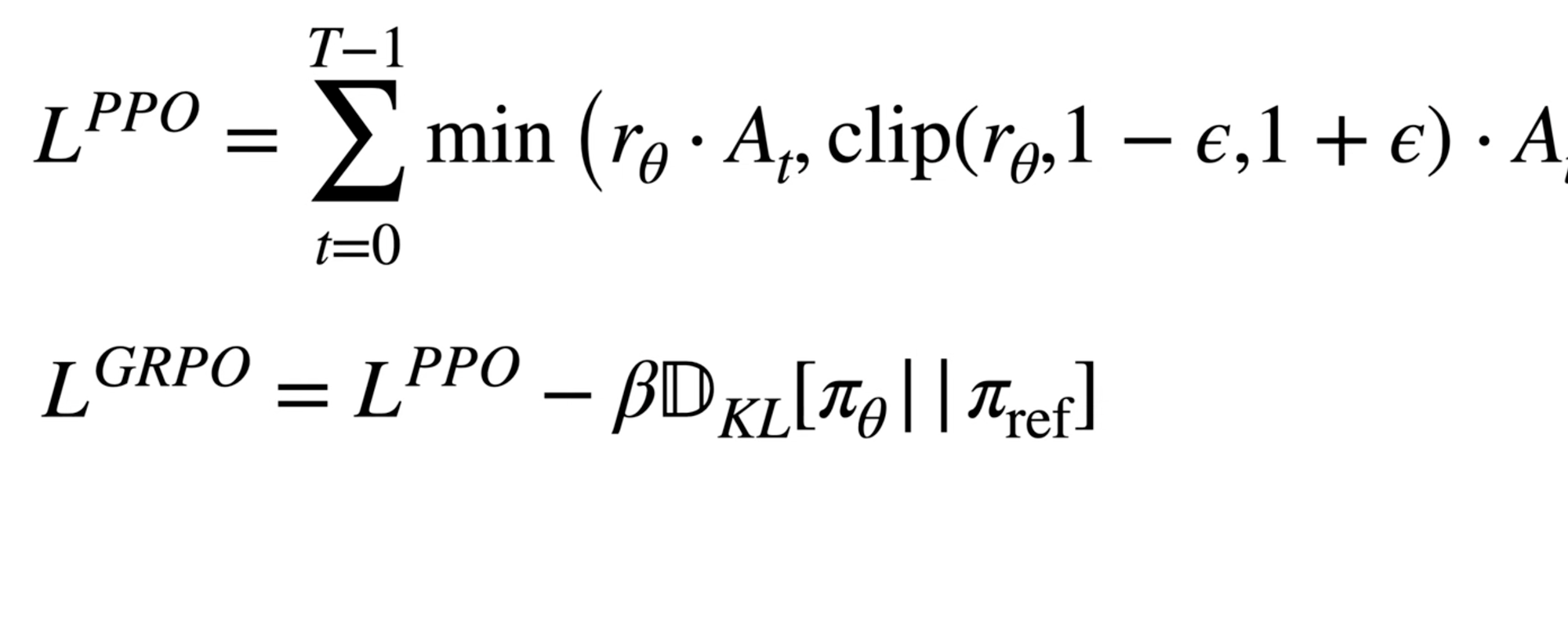
This addition is essentially a mathematical anchor used to compensate for the increased variance introduced by GRPO’s simplified design. Since GRPO removes the State Value Function (the "Critic") to significantly reduce memory and computational overhead, it loses the fine-grained guidance that helps traditional PPO stay stable. The KL divergence term serves as a necessary regularization mechanism, preventing the model from degenerating or "drifting" too far into noisy, unrecoverable states during the optimization process.
Lastly, I want to reference this visualization which simplifies the key difference between PPO and GRPO