Progress on LLMs
The field of NLP has made tremendous progress in last 10 years. These Deep Learning approaches, from Word2Vec to GPT4, show remarkable capabilities can be achieved through representation learning.
Tracing the journey back 5 years shows progress has mostly been to scale and engineer these LLMs on data and compute. There definitely are new ideas since transformer, but they’re mostly refinements, and that too without ablation studies. Notable ideas include:
- Reinforcement Learning through Human Feedback (RLHF) to fine-tune LLMs to dialogue
- Various minor (but important) improvements to transformer, including learned positional embeddings, scaling number of attention heads, etc
- Joint embedding pre-training across multiple modalities
On the other hand, the engineering feat has been a tremendous achievement. Ideas and algorithms from Megatron and DeepSpeed enable fast parallel training. But at the scale of modern LLMs many more challenges come up that need to be carefully engineered.
Product considerations include:
a) Costs of training-test iteration
b) Careful preparation of dataset, which is one of the main secret sauces to these LLMs
c) Model alignment toward trust and safety objectives
Technical challenges include:
- Numerical instability and tricks to handle mixed precision training
- Massive Parallelism: model and tensor parallelism across hundreds of GPUs, mitigating communication bottlenecks, handling machine failures, and even optimizing datacenters for fast GPU interconnect bus
- Memory management: which is even more challenging with model parallelism as different parts of the model are stored and accessed on different devices
- Parameter initialization to ensure model converges quicker
- Careful management of regularization techniques
Basically, the problem of training massive scale and complexity of models require careful management of computational resources, optimization algorithms, and regularization techniques to ensure successful training and accurate results.
LLM Progression
Here my list of models progression and scale increase:
| Developer | Release | Size | Modality | Innovation | |||
|---|---|---|---|---|---|---|---|
| GPT 1 | OpenAI | 2017 | 117M | Text | Transformer architecture for pre-training and fine-tuning | ||
| BERT | 2018 | 100M | Text | Bi-directional transformer | |||
| GPT 2 | Open AI | 2018 | 1.5B | Text | |||
| XLNet | CMU/Google | 2019 | 340M | Text | Permutation training, Autoregressive and autoencoding objectives, Relative positional encoding | ||
| RoBERTa | Facebook AI | 2019 | 355M | Text | Optimized training of BERT architecture | ||
| GPT 3 | OpenAI | 2019 | 175B | Text | Large scale transformer architecture | ||
| BlenderBot | Facebook AI | 2019 | 4B | Dialogue | Architecture for multi turn dialogue | ||
| Meena | 2019 | 2.6B | Dialogue | ||||
| Ernie | Baidu | 2020 | 260B | Text | Incorporates external knowledge sources into BERT architecture | ||
| ViT (vision) | 2020 | 86M | Text and Image | Transformer architecture applied to vision | |||
| Gopher | 2020 | 280B | Text and Dialogue | Multi domain dialogue architecture | |||
| Megatron | Nvidia, Microsoft | 2020 | 530B | Text | Large scale and efficient parallel training | ||
| Jurassic-1 | AI21 | 2020 | 178B | ||||
| Codex | OpenAI | 2020 | 12B | Code | Training on code | ||
| CLIP | OpenAI | 2021 | 400M | Text and image | Joint pre-training of vision and language models using a contrastive learning framework | ||
| T5 | 2020 | 11B | Text | ||||
| ChatGPT | OpenAI | 2021 | Chat | Instruction tuned using RLHF | |||
| GPT 3.5 davinci | OpenAI | 2021 | 175B | Text | |||
| LaMDA | 2021 | 137B | Text and Dialogue | ||||
| xlarge | Cohere | 2021 | 52.4B | Text | |||
| GPT NeoX | EleutherAI | 2021 | 20 | Text | Improved training efficiency for large-scale transformer models through the use of sparsity and parallelism techniques. | ||
| GPT4 | OpenAI | 2022 | 1T | Text, Image, Code, Dialogue | |||
| LlaMA | Meta/Facebook AI | 2022 | 65B | Text | |||
| Toolformer | Meta/Facebook AI | 2022 | 6.7B | ||||
Evaluation Benchmarks
As models progressed and achieved better-than-human performance on early made-up tests, the set of NLP evaluation benchmarks have evolved and matured considerably. Popular benchmarks include:
- Language Modeling: These benchmarks evaluate the ability of the LLM to predict the sequence of words in a given context.
- Penn Treebank, WikiText-2/103, and Enwik8.
- Question Answering: These benchmarks test the LLM's ability to answer questions based on a given context.
- SQuAD, TriviaQA, and CoQA.
- Text Generation: These benchmarks evaluate the LLM's ability to generate human-like text.
- GPT-2 and GPT-3’s human evaluation tests, and The Pile.
- Text Classification: These benchmarks test the LLM's ability to classify text into different categories.
- IMDB, AGNews, and SST-2.
- Dialogue Modeling: These benchmarks test the LLM's ability to participate in human-like conversations.
- ConvAI2 and Persona-Chat.
- Multi-modal Benchmarks: These benchmarks test the LLM's ability to process and understand both text and other modalities such as images, videos, and speech.
- VQA and Flickr30K.
- Cross-lingual Benchmarks: These benchmarks evaluate the LLM's ability to work with multiple languages.
- XNLI, MultiNLI, and Tatoeba.
- Commonsense Reasoning: These benchmarks test the LLM's ability to understand and reason about common-sense knowledge.
- CommonsenseQA, SWAG, and HellaSwag.
It has become common practice now to test LLMs for logical and common sense reasoning, bias, ability to keep track of information, and carry out downstream tasks. Some common ones include:
- Big-Bench, 200 benchmarks for language model evaluation
- Arithmetic benchmark 3-digit add/sub 2 digit mult
- Truthful QA, OpenBookQA
- Grounded conceptual mappings
- MMLU or Massive multi task language understanding
- Word in context semantic understanding benchmark
- Lambada benchmark - contextual word prediction
- Hellaswag - sentence completion
Selected Models
But first, a quick detour.
When we talk about scaling to large models are we talking about: Model architecture, Training data, or compute FLOPs? There is some recent research studying these factors against performance, but more on that later.
- Parameters: is the number of free-variables model has to learn. It is influenced primarily by a) model architecture (layers and components, dimensionality), as well as number of tokens used to represent the vocabulary, which is generally correlated with data size.
- Training data size: represents the vastness and diversity of examples the model sees.
- FLOPs: measures training compute resources and is a function of both data size and parameters, among other factors like training epoch.
The GPT Family
There is little technical details on GPT models, except that it scales to very large sizes (parameters as well as data).
GPT 1 started with decoder only transformer architecture with 12 layer and heads and a smaller context size of 512. Since then GPT 2, 3, and 4 have increased layers, heads, and context. Other notable changes are learned positional embeddings (unlike original transformers), adding layer norm to input and final blocks of transformer, scaling weights and in GPT3 moving to sparse attention technique, presumably for computational savings.
Besides these and possibly many more architectural changes, the GPT family scales on both training data size as well as parameters, going from 117M in GPT-1 to 1 trillion in GPT-4!
There is not much information on computational architecture for distributing the model, but one should safely presume engineering scale is the real achievement of OpenAI’s team.
Megatron
Unlike OpenAI, Megatron paper revealed a lot more technical details.
The paper introduced model parallelization techniques, in particular, tensor-parallelism, a step up from model pipeline, the prior state of the art. More recent LLM architectures employ model parallelism within matrix multiplication (megatron style), and model parallelism across layers of the network.
Gopher
This paper by DeepMind goes into a lot of details about making large scale training work.
They use RMSNorm, Relative positional encoding, and SentencePiece encoding, model parallelism and gradient checkpointing. Their dataset was much smaller than GPT3. 10TB vs 40TB
Chinchilla
The paper "Training compute-optimal large language models" by DeepMind attempts to understand scaling laws, and in doing so, falsified prior belief that model size mattered the most. This was one of the more scientific studies, and they even tested the hypothesis by training a 70B parameter model with fixed compute budget that outperforms larger models, including Gopher and GPT-3.
Prior to this OpenAI's research concluded that model-size has outsized impact on performance. So, the engineering quest to scale to insanely large models had started.
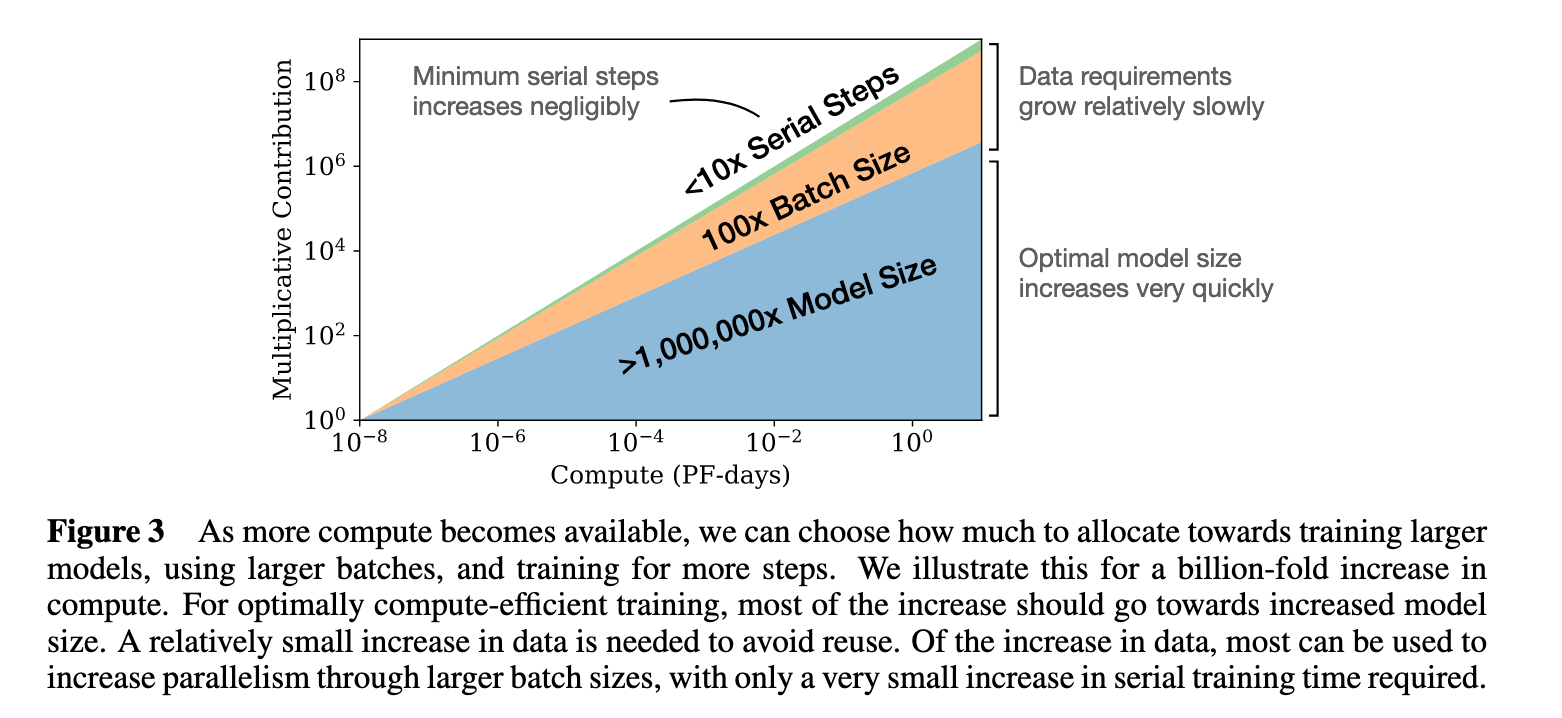
DeepMind questioned this conclusion. They asked the question: for a given compute budget, what scales optimally: model size or data-size?
They picked several curves (compute budget) ranging from 10^18 FLOPs to 10^21 FLOPs and trained models of various sizes.
What they learnt was that there is an optimal ratio (the green line below).
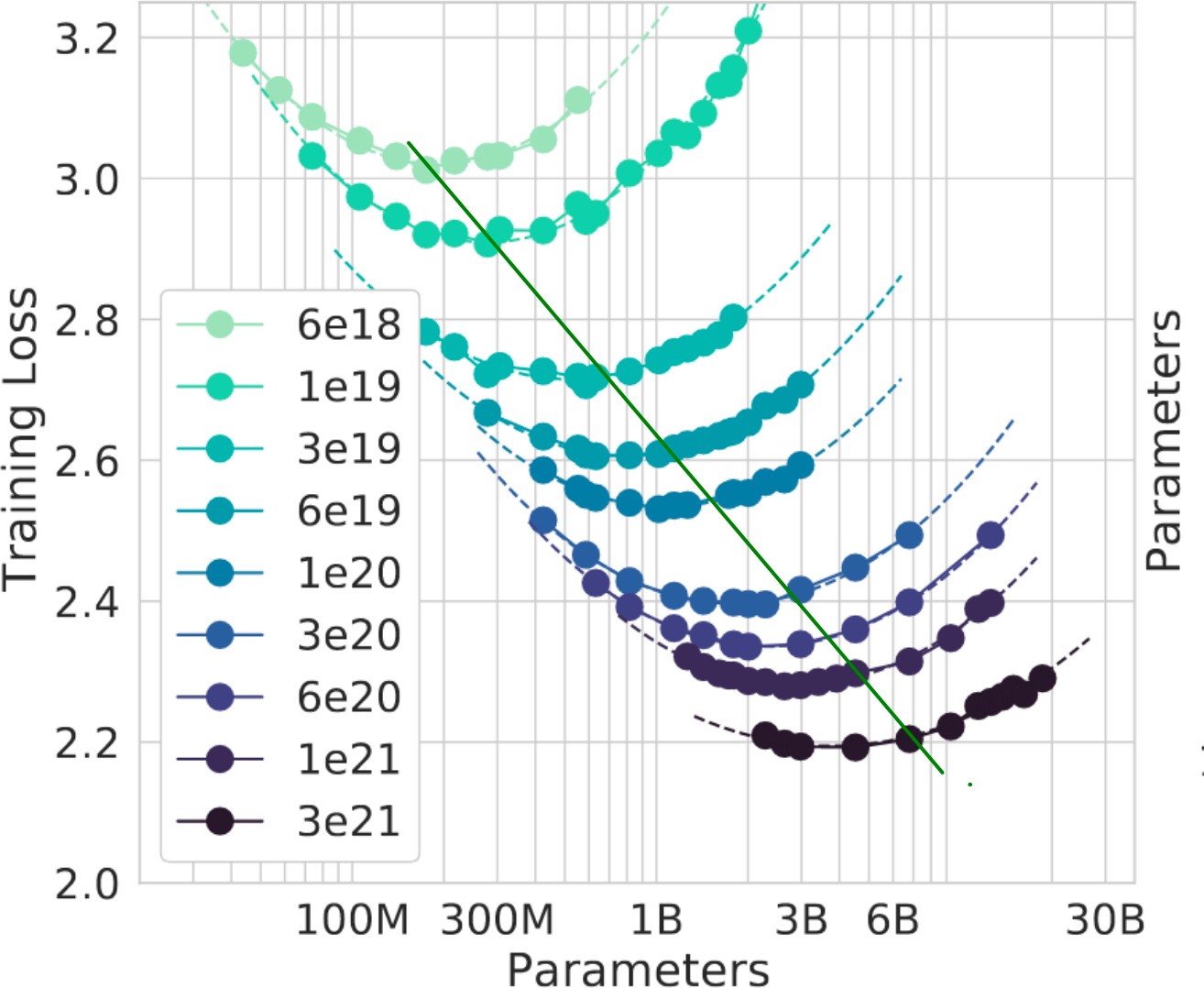
Interpretation:
* Each point shows loss for parameter/data-size ratios for a fixed compute budget
* Pick a curve. Lower the loss, the better.
* Pick the lowest point (optimal model)
* On left the model should have been larger.
* On right the, a smaller model with more data would have been better.

To validate this hypothesis they trained a 70B parameter model called Chinchilla using same amount of compute as Gopher. Chinchilla had 1.4 trillion tokens where Gopher only had 300B token training. Just as they predicted, it beats Gopher model on all metrics of MMLU set.
What this means is that most large LLMs were wasting compute on parameters. Here is a chart DeepMind put up to reference optimal size:
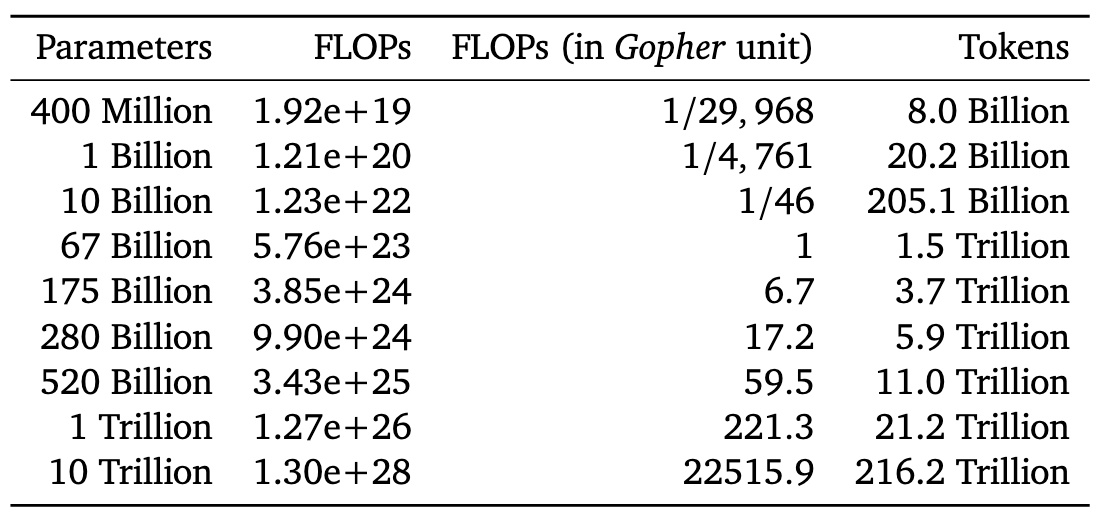
We don't know if GPT-4 followed this schedule or not, but it basically concludes that you don't 1T parameters (GPT4's) unless you have a 200x more compute.
…
References: