Reasoning in LLMs
I've been thinking about reasoning abilities in LLMs. To what degree do they exhibit reasoning abilities vs reformulation via statistical patterns? After all, they are increasingly referred to as "reasoning-engines" these days, but do they reason?
I also came across an interesting post that solidified some of my thoughts in here.
Reasoning
First, lets crystalize what we mean by reasoning. There are innumerable interpretations, of which I like this simple idea: derivation through multiple steps of inference over an abstraction of the concept - that is, being more general than a particular example.
CoT methods, including few-shot or zero-shot, hint that LLMs may be able to reason, and by controlling the machine to follow smaller, more tractable steps, it is able to get the right answer more often. That is, CoT in itself is not reasoning, but it showcases that the LLM has learnt the ability to reason.
Evaluation
All LLM evaluations suffer from data-leakage as they were trained on web data that directly or indirectly hinted on the evaluation questions. The open benchmark that require reasoning abilities like ARC, MQTT, HumanEval(code) etc are therefore not a good measure of their true abilities.
Are LLMs a 'reformulation machine' or 'reasoning machine'?
This statement captures my intuition, that these are not discrete abilities, rather they may lie on a continuum.
The question of “memorization” versus reasoning is not all-or-nothing; Wu et al. noted that in LLMs there is “some degree of reasoning that is transferable between the default and counterfactual worlds. [Memorization and reasoning are] not a dichotomy, but rather they can co-exist in a continuum.”
While a model may do both, we can still measure how well it performs at both ends of the spectrum.
Intuitively, in order to test if a person has remembered and partly-understood a new concept we ask them to explain it back by reformulation. In order to test if a person has deeply understood a new concept, we ask them to apply it to an unseen or unrelated situation. I believe this intuition should be sufficient for LLM-machine as well.
For example, we can invent a new numeric system with different characters and a base and ask ChatGPT to perform arithmetic in that system. Most grade-schoolers can easily translate their learnt knowledge of mach on this new character system.
That is also the basis for an exploration in this paper that uses counterfactual-tasks to test GPT-style LLM's ability to translate its learnt principles as these formulations are unlikely to be in the training data. They test it across various abilities, for example:
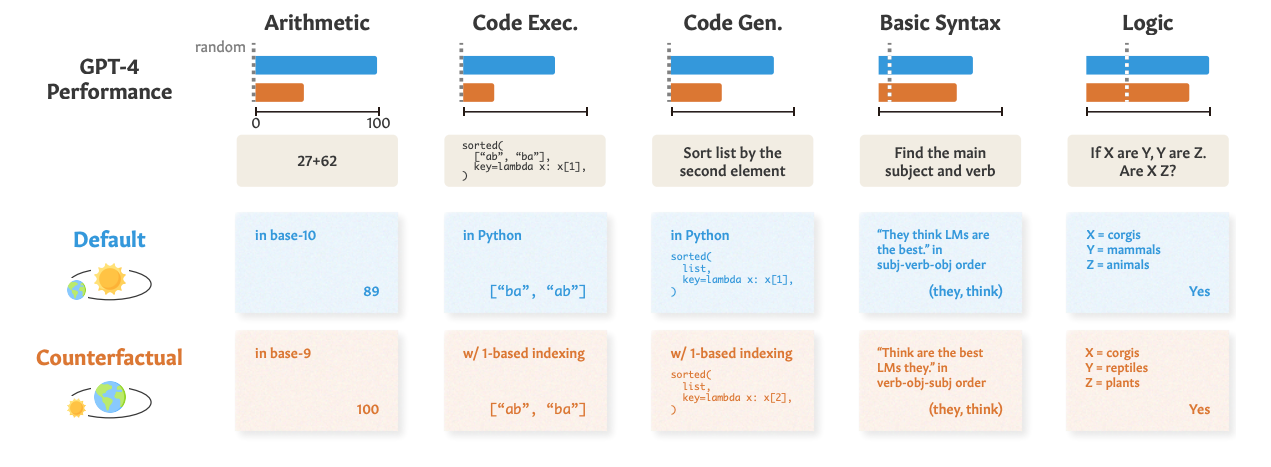
And snapshot of the results:

Credit: Wu et al paper Reasoning or Reciting?
What can we conclude form these results:
- In most tasks, counterfactual framing underperforms default prompt.
- GPT-4 is significantly better than 3.5, Claude, Palm-2 at abstract reasoning.
- There is clearly some degree of abstract reasoning that is going on in these machines.
(1) is not surprising as LLMs were not trained to produce rotated image or change bases in its arithmetic. The prompts are out-of-distribution, and I suspect by training on such corner-cases we may be able to generalize these LLMs even further.
That might be how GPT4 outperforms all others. A combination of scale and distribution of data clearly seems to improve reasoning and generalization ability of these LLMs.
While this charts a clear path to improving reasoning and generalization, it does remind us how inefficient our current AI approaches (auto-regressive, RL, etc) are compared to human learning and generalization experiences - that is , a lot more datasets are required to reach human-level abilities.
Limitations
There may be two structural limitations: mode and architecture.
If the machine has only ever seen text, lacks the contextual grounding of experiences, of visual and auditory senses, then does it really understand an idea well enough to reason over it? It can only derive from the textual patterns it has seen, which may be out-of-mode.
The limitation of current architectures and approaches are evidenced by lack of efficient learning and longer-term execution, including memory and planning. These are actually research green-fields and could be solved in few years.
Utility
Despite these limitations, even semblance of reasoning could broaden applications of LLMs technology.
Today we use ChatGPT primarily to reformulate known information. With improved reasoning, we could generalize LLMs to lot more situations, and ultimately derive net new knowledge about a system.