Reinforcement Learning and RLHF in a nutshell
A very high-level summary of RL.
Dall-e's somewhat inaccurate representation of RL state-space
RL is an approach to efficiently search state-space of a well-defined system. We can think of the system as a graph with states (vertex) and actions (edges) that lead to change in state. In its finite version, it is a game with start, end and a result, that leads to a reward e.g. win/lose the game.
LLM and Vision conv-nets and autoregressive architectures are fundamentally about uncovering semantics through compression bottleneck and with a small working memory (context window), but lack the notion of interaction with its environment over time sequence. Therefore, they lack planning and interaction. RL is about the latter - exploring and learning from its environment.
The advantage of RL over supervised learning is that optimization objective does not need to be differentiable, as long as reward samples r are available.
If you have come across dynamic-programming problems, you have the intuition behind RL. We can reduce the computational complexity of search by memorizing reusable, intermediate results. Traditionally used for robotics, but found easier to make progress in simulation like games (atari, alpha go, chess) because it also suffers from needing many samples.
Limitation:
Like most of DeepLearning today, RL also suffers from sample inefficiency. AlphaZero played 44 million simulated games during its training. While its the state-space of chess is vast (10^120), 44 million games is more than any human could possibly do, because it relies on inductive logic rather than deductive reasoning. Nevertheless, its a bit more smarter and efficient than rote memorization or exhaustive search of the entire tree.
I think there are opportunities to combine semantic understanding from ML and search from RL to carry out more deductive, semantically well-reasoned search, leading to better sample efficiency, and perhaps applicability to greater classes of problems.
RLHF, popularized by ChatGPT, carries very few human-labeled samples. In fact, the trick is that human feedback is used to train the reward function only, and then the game is played AI vs AI. Both, agent and environment are AI. More on RLHF a bit later.
Basics
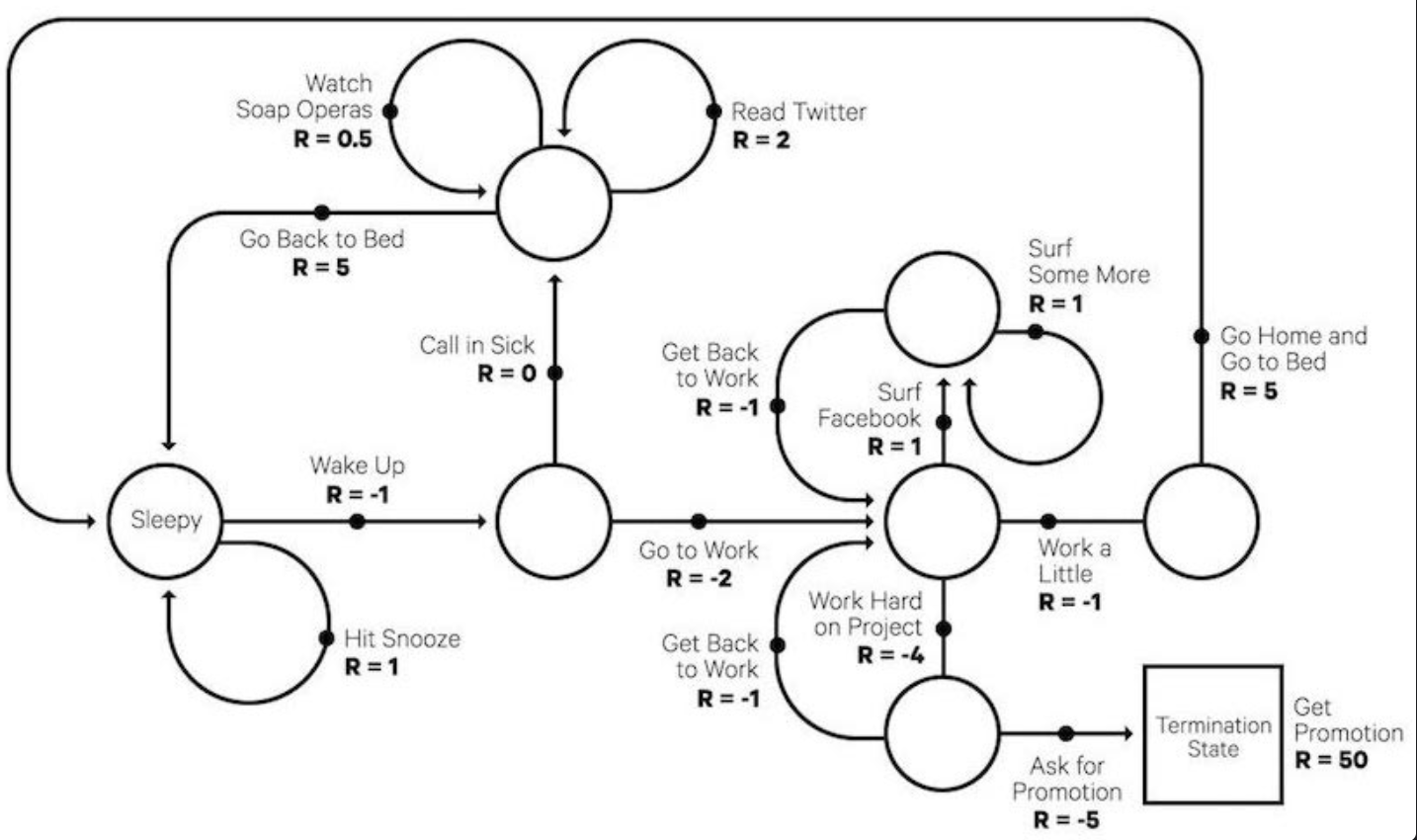
- A game is played in episodes, where reward or a result is revealed at the end of the episode. For example, playing atari, you take actions and eventually either win or lose the game. Each game is an episode, each keystroke is an action, and each pixel is part of the state-space.
- A policy: π is an algorithm for picking the optimal action.
- Value: is the value or Expected reward of being in a given state.
- The goal of training is to learn the optimal policy, and use it in future gameplays. This is akin to being an expert player.
- We can learn value function and pick policy that maximizes the value, or learn the policy function directly.
- If we lean the value at each state, encoding explore-exploit into policy is necessary to uncover new territory. Its a good idea for Policy to output distribution belief over all values.
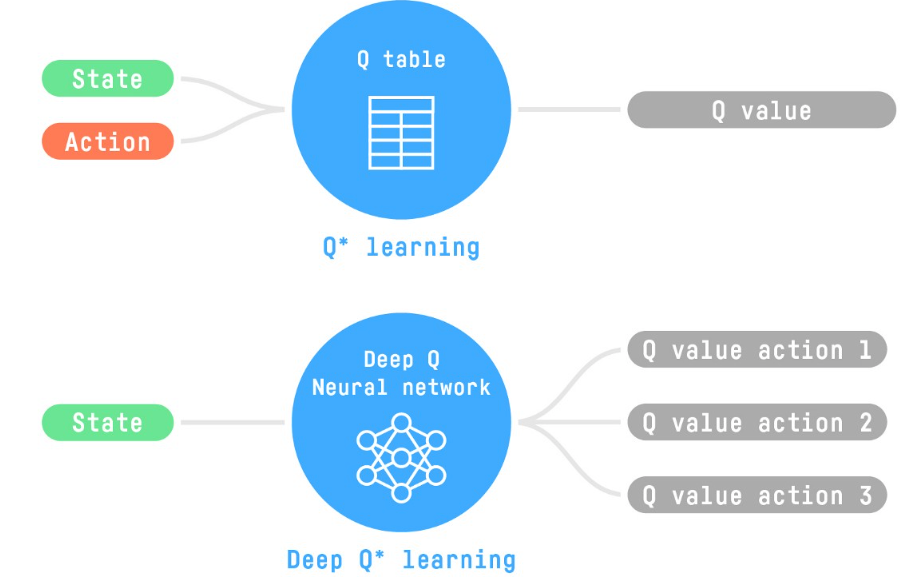
- A Q-table (Q stands for quality) is a memory for mapping state-action to its expected reward that the system believes (has learnt). Initially it is random and starts converging with exploration.
- Monte Carlo vs Temporal Differential learning: Two common approaches to learning the value function. Monte Carlo - update quality estimates after an entire episode when the reward is concretely known. TD - update quality estimate after each move, estimating subsequent reward based on previous model.
- On policy, off policy: on-policy means stick to the same algorithm for entire episode. Off-policy means keep updating the policy algorithm.
Techniques to maximize rewards without access to gradients of reward function:
Single Step:
- Value Learning
- Policy Learning: Stochastic Policy Gradients
 Lilian Weng
Lilian Weng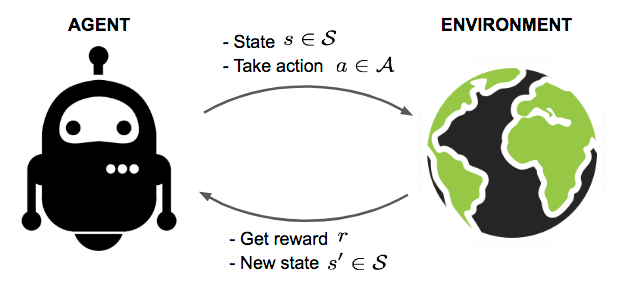
Data Collection and Exploration
Sequential Decision Problems:
- Off-Policy RL - Temporal Difference, Actor-Critic
- On-Policy RL - Reinforce, Proximal Policy Optimization
Q Learning
Updating Q Value

Q-Table mapping only works for small action-state spaces to be stored in memory. In problems like video-games or self-driving vehicles the action space is gigantic and it is better to approximate the Q-values using a parametrized Q-function:
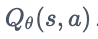
Our Deep-Q NN will approximate the different Q-values for each possible action at that state.
Policy-based methods directly learn to approximate optimal policy without having to learn a value function, for example, using a neural network that will output a probability distribution over actions.
In policy-based methods, we search directly for the optimal policy. We can optimize the parameter θ indirectly by maximizing the local approximation of the objective function.
Policy-gradient methods is a subclass that optimizes the policy directly by estimating the weights of the optimal policy using Gradient Ascent.
Actor-Critic
Actor-Critic method is a hybrid architecture combining value-based and Policy-Based methods that helps to stabilize the training by reducing the variance using:
- An Actor controls how our agent behaves (Policy-Based method)
- A Critic that measures how good the taken action is (Value-Based method)
Deep Q Learning
Reinforce
Proximal Policy
Clipped surrogate objective function