Transformers - Part 1 NLP
Transformer architectures have unlocked tremendous potential in the context of Machine Learning problems. It has become the basic building block for learning and generating all modalities: language, vision, speech.
But what changed with Transformers? We had kernel methods available for decades. In short, transformers allows for efficient context-aware learning. A single dimensional sequence of n tokens would normally have O(n^2) parameters to learn for a binary relationship context, O(n^3) for ternary, and so forth. Transformer allows learning these in compact representations, mitigating bottlenecks of Recurrent-Neural-Network (slow and sequential learning), and unlocking scaling to larger context. Thus, we can see Transformers are an efficient methods of learning kernels that map a high-dimensional space of token representation, to a lower dimensional space, while preserving properties that discriminate tokens for a given learning objective, what you might call its "semantics".
In this note I will try to summarize key ideas and intuition that are worth remembering. I will start with language modeling and cover Vision Transformers in a subsequent note.
Recurrent Neural Networks
Sequential RNNs suffer from a bottleneck - the hidden representation must encode information about the text seen so far in a sequence. This makes them slow, makes it hard to encode far-away dependencies (who knows what'll be useful later), and is generally hard to learn as back-prop error signals get toned down across recurrence steps (vanishing-gradients problem)
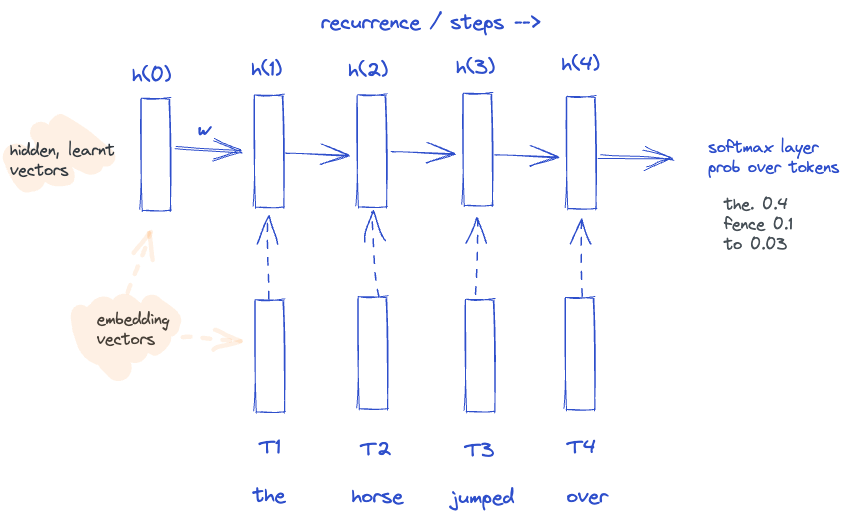
As the sequence gets longer, more information would have to be squeezed into a single vector. Instead, use multiple vectors by including all 4 hidden states for h(4) time-step. This is the basic intuition behind attention.
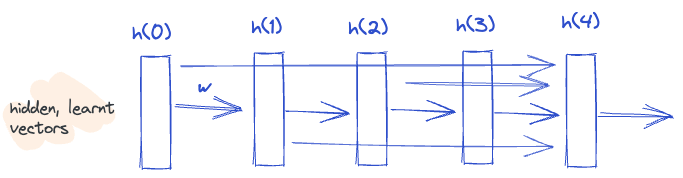
But, this is extremely inefficient with an explosion of parameters.
Attention
Query, Key
Attention framework follows information-retrieval terminology to formulate a lookup table. It includes:
a) query - a source token representation whose semantics we are trying to learn,
b) key - target token from the nearby context whose importance we want to determine while learning semantics of the query token.
A simple intuition behind attention is following way of solving RNN's bottleneck and vanishing gradients problem in the context of sequence-to-sequence learning such as machine translation i.e. directional and no look-aheads.
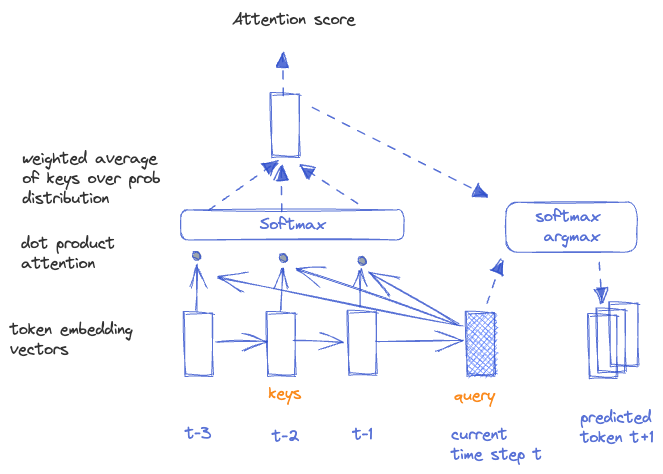
Note that in this model attention vector is calculated at every timestamp.
This provides shortcuts to far away sequence states, avoiding both bottleneck and vanishing gradient challenges from RNNs.
Attention mechanism has explored several variants but even simple dot-product works well in practice.

Self Attention
Attend on the same sequence being predicted on, or in other words, look at its own surrounding as context. Some other problems require attending across auxiliary datasets, which are not self-attention.
RNN's "recurrence", where timestamp n depends on timestamp n-1, make RNNs non-parallelizable and slow. Can we compute all token's hidden states in parallel? Yes, with self-attention.
Note, parallel here mean not depending on other hidden states, but still taking the dependency on context tokens. The contextual knowledge, instead of being learnt incrementally, gets learnt in parallel.
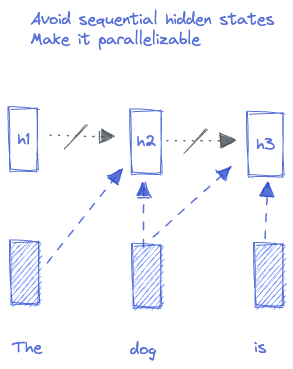
In the RNN example, Query and Key were the same vectors. Here we will separate them out and introduce one more construct: value vector.
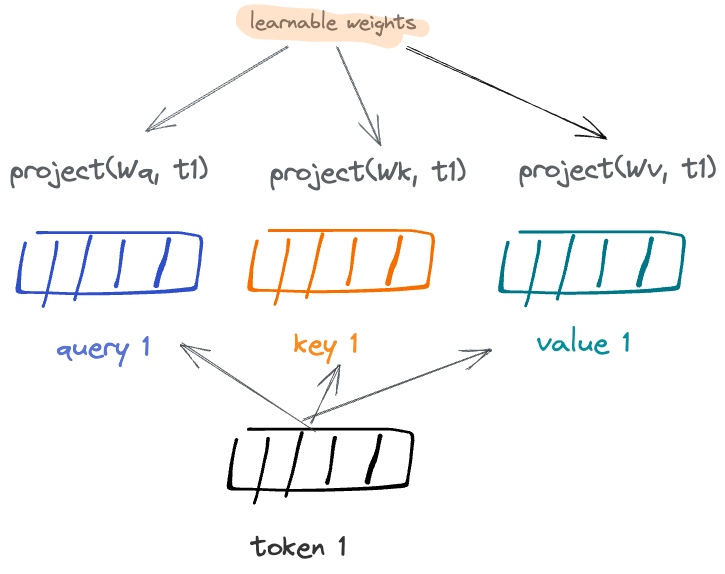
This can be interpreted as: Use the representation of word at current position (query) to find the most helpful/relevant word that occurred previously through its representation (key). Here, representations are projections (think kernel) controlled via learnable weights. The Value is yet another mapping between key and value. I have not found an intuitive interpretation, and it may simply be an alternate way for the net to representing the key projection.
Having each of these Wq, Wk, Wv separate learnable weights (as opposed to same) gives the model more flexibility in how to represent the lookup-table. These blocks are often called "heads" and are often duplicated with the intuition that each one may capture different linguistic property of a dataset.
How does self-attention remove recurrence and allow parallelization?
Learning the representation at a given timestamp involves itself and its context's projections, which are shared across all tokens/time-steps, thus removing incremental predictions from the architecture.
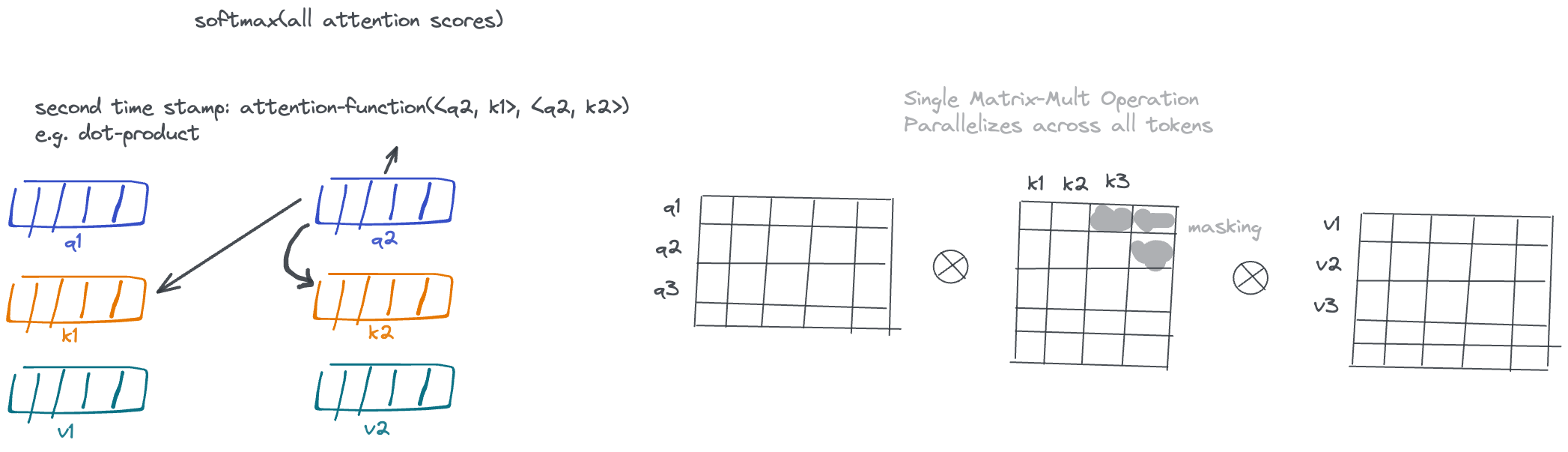
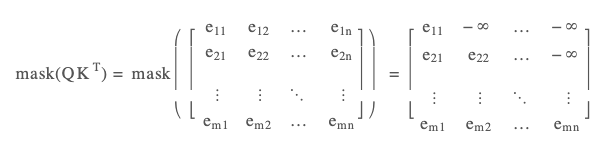
Because multiple timesteps share the same projections, these operations across all tokens can be performed in parallel, and usually implemented through a large matrix-multiplication operations, for which we have fast algorithms in place. The masking steps on keys is problem-dependent, and in the context of language modeling or machine translation, ensures attention queries at a given timestamp can not see the future tokens, since that's we are going to be inferring tokens sequentially at testing time. This masking is implemented by multiplying with a masking matrix that will suppress illegal connections.
Position Embedding
What about order of tokens?
TODO
Learned. but original was not.
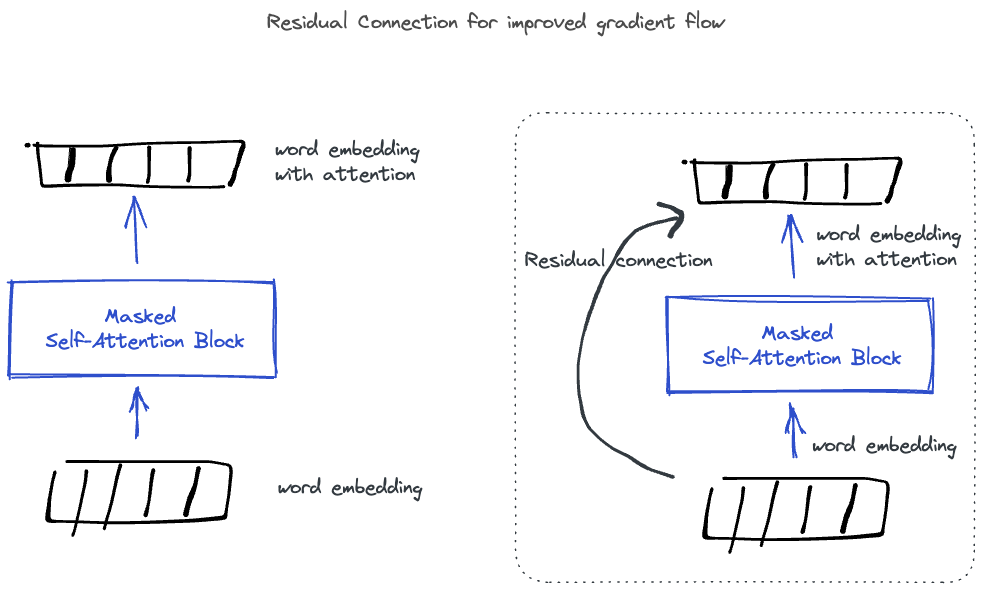
Residual Connection
One additional trick worth mentioning is this residual connection. It is nothing but a direct connection between word + positional source embedding and the final attention vector. It was added to help with the gradient flow and be able to train much deeper models. (reverse the arrows to think of it in terms of error back-propagation)
Transformers
Sequence-to-Sequence Learning
In seq2seq language modeling inputs and outputs are both sequences of words, for example language-translation from english (e) to french (f). This can be mathematically written as:
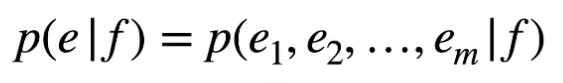
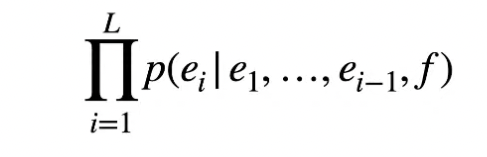
Encoder-Decoder Architecture: Seen as 2 separate networks
- encoder network: responsible for coming up with vector representation of source sentence
- decoder network: responsible for constructing target language sentence from the smaller, encoded representation
Multiple Attention Heads
What we've seen so far is a single-head of an attention block. Adding multiple such heads to the same attention translation allows the model to focus on different structural properties, for example, different linguistic properties. It is also thought to benefit in increased model parameters, and therefore, more opportunities to learn and memorize knowledge.
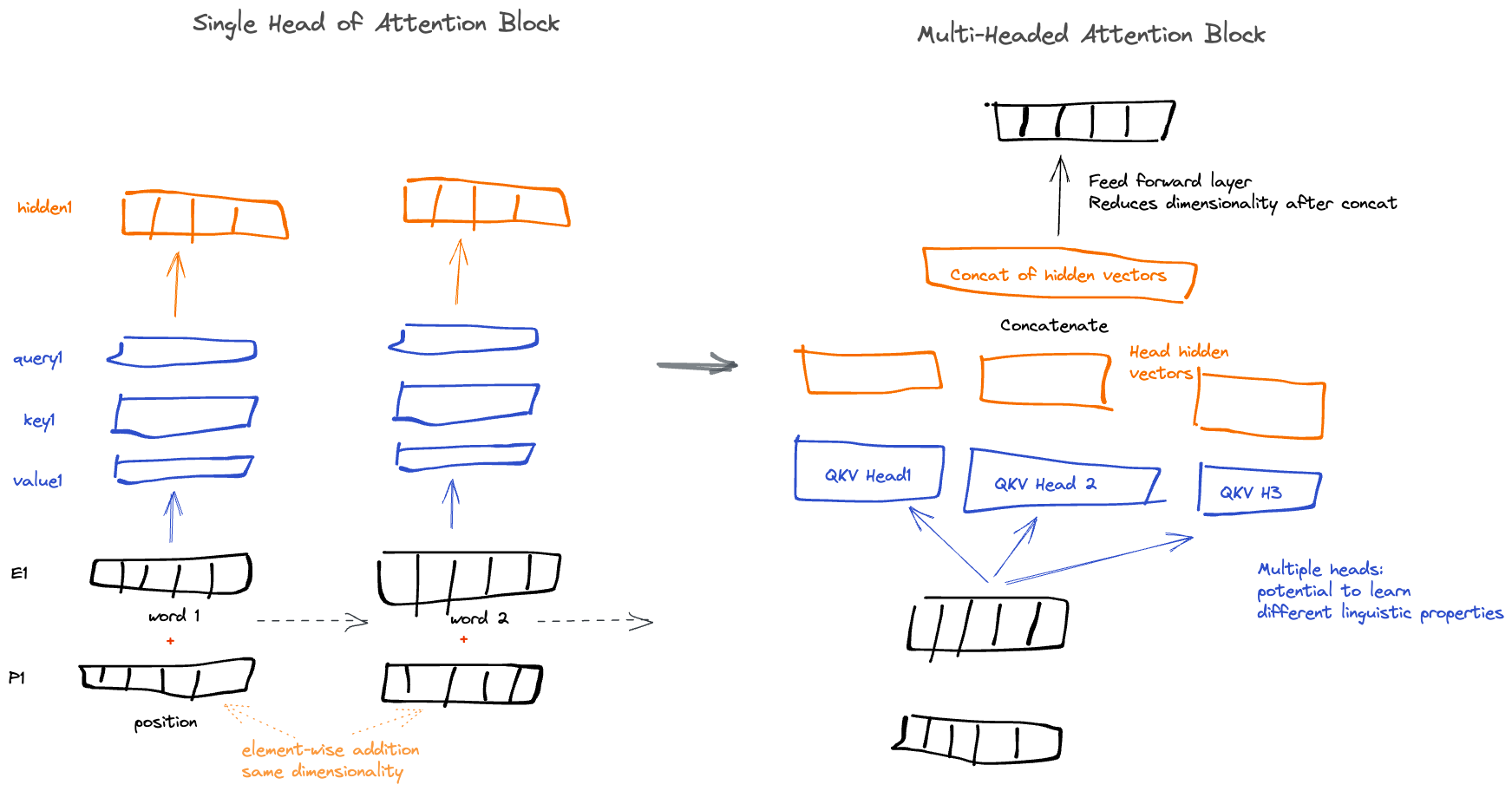
These heads can be randomly initialized, and sometimes, there are tricks to initialize them for efficient learning, regularize, ensure redundancy, etc. Modern LLMs carry 100s of heads in their transformer block, and also multiple transformer blocks layered on each other. One thing to note is each head and each layer has its own weight parameters (Wq, Wk, Wv) to learn.
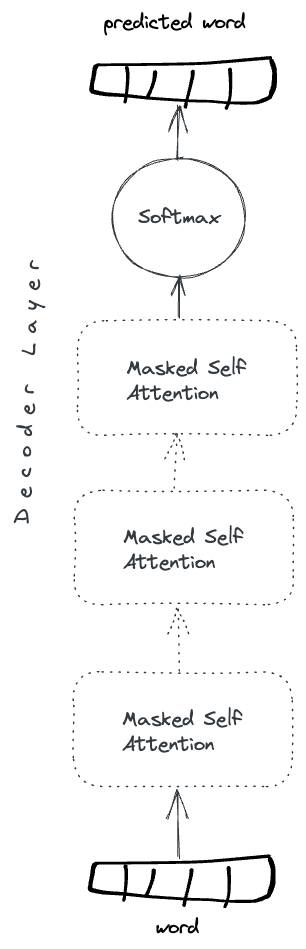
Why stack multiple transformer layers?
I don't know of a good theoretical explanation but I suspect that it a) it introduces more parameters to learn and encode knowledge, and b) it forces the model to learn over a series of increasingly abstract formulations.
Final Piece: Cross Attention
In a seq2seq transformer framework, such as machine translation, encoder embeds, and decoder generates.
Encoder: In machine translation task the source sentence is entirely visible at testing time. Therefore, the encoder is an Unmasked Self Attention block. In other words, learning semantics of token at position t can contextualize around tokens that came before or after. Since the encoder is not prediction probabilities we also omit softmax layer on top of the attention vectors.
Decoder: The decoder is a masked self-attention block that can not peek or look ahead during testing time. It has access to earlier tokens in the sentence, but in the context of translation, also needs access to the encoder embeddings in order to translate sentence in source language into target sentence. This is possible by the means of Cross-Attention. Here, the query vector, and every step t, attends over KV representations of all of source sentence tokens. (which is also unmasked)
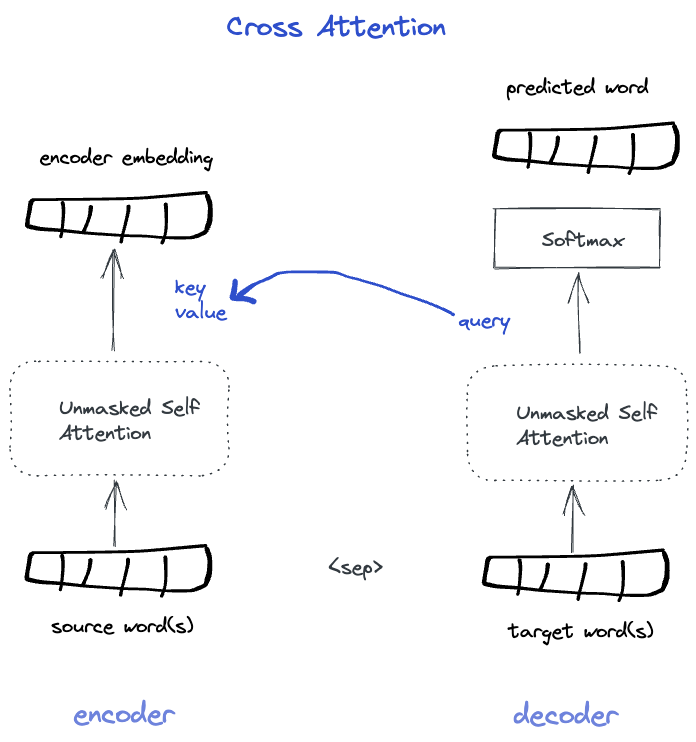
The decoder block performs masked-self-attention over its own sentence and cross-attention over encoded, source language tokens. This cross-attention mechanism is added at every layer, and in most architectures, the KV attended-to are encoder's final layers, but can be intermediate layers too
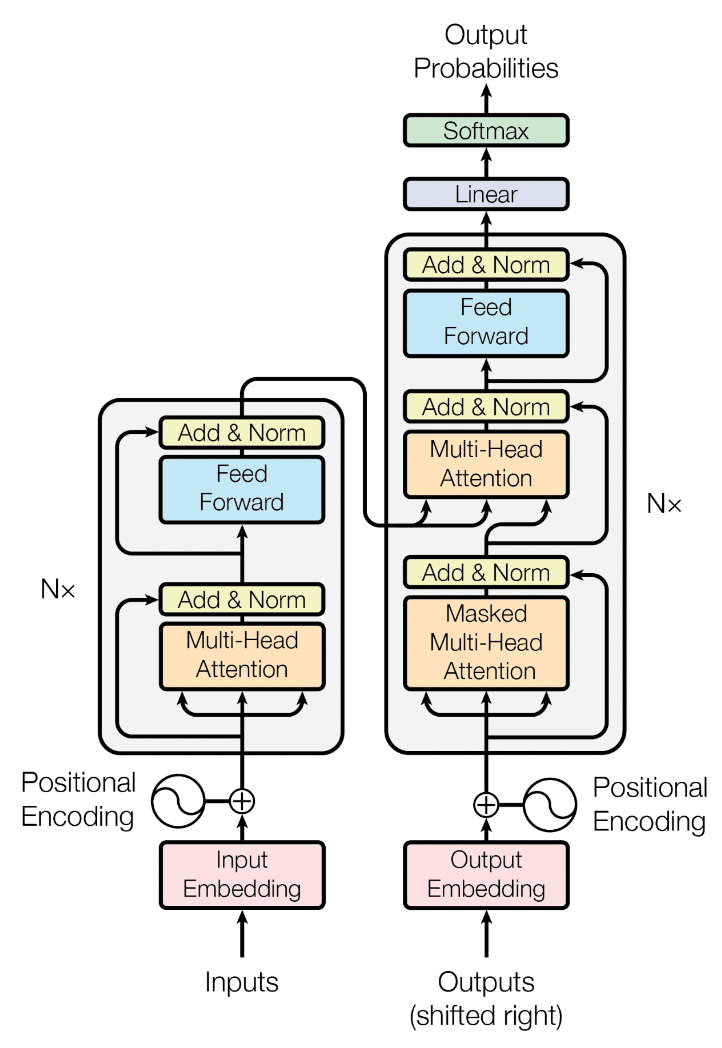
Now, putting all this together, this figure from the original Transformer paper should make sense.
Common Tokenization and Encoding Schemes
Word-level tokenization misses sharing information between work forms, roots, and its lexicography structure. It is also poor at dealing with out-of-vocabulary words that the model might encounter at inference time. It it too coarse.
Character-level tokenization on the other hand, can deal with out-of-vocab words, but poses too much complexity for the network. For example, self-attention's becomes slow as its complexity grows quadratically.
There is a middle-ground (BPE) however as we'll see, people have navigated to taking the complexity hit in favor of flexibility for multilingual datasets.
1. Byte-pair Encoding (BPE)
Details on hugginface docs
Pretokenization Step: removes white space and normalizes the raw dataset. Without this step the encoding algorithm would have to deal with formatting and structure as well.
Step 1: Compute unique set of words from your dataset and find all symbols (initial vocabulary). This typically includes ascii and some unicode symbols.
Step 2: Merges: Find most common pairs in a sequence and merge them into a single token. Iterate until some criteria is met.
Vocabulary: ["b", "g", "h", "n", "p", "s", "u", "ug"]
Corpus: ("h" "ug", 10), ("p" "ug", 5), ("p" "u" "n", 12), ("b" "u" "n", 4), ("h" "ug" "s", 5)
Vocabulary: ["b", "g", "h", "n", "p", "s", "u", "ug", "un"]
Corpus: ("h" "ug", 10), ("p" "ug", 5), ("p" "un", 12), ("b" "un", 4), ("h" "ug" "s", 5)
Vocabulary: ["b", "g", "h", "n", "p", "s", "u", "ug", "un", "hug"]
Corpus: ("hug", 10), ("p" "ug", 5), ("p" "un", 12), ("b" "un", 4), ("hug" "s", 5)
Similarly, SentencePiece has been experimented with byte-level encoding for multilingual models, for e.g. mT5 (multilingual with T5 denoising objective) with word-level SentencePiece encoding to ByT5 (byte-T5, or byte level encoding, which better suited multilingual dataset), although was 7x slower even at inference. Byte-level encodings are also robust to noise like spelling errors.
Word Piece Encoding
Similar to BPE but merged by likelihood not by frequency.
Sentence Piece Encoding
Similar to word-piece but non-deterministic on the dataset as it can be influenced by training step. It is also good for languages that don't separate words with space, including multi-lingual models.
Prior to pre-trained transformer models any given problem domain would have to have the RNN learn fundamental linguistic properties and general knowledge from its own labelled data.
ElMO model: trained RNN foundational model and transfer-learn on a specific domain by replacing token-embeddings with hidden-states from the ElMO LM.
RNNs are inherently sequential, but it is helpful to contextualize a word within the entire sentence. ELMo tried to solve for this with two separate LMs: forward and backward LMs, concatenated together - a hacky approach.
This was before the Transformer was introduced. This idea combined with transformer architecture resulted into BERT.
BERT: Autoregressive Encoder
Masked Language Modeling: sequence where some tokens are randomly masked off. Objective of the network is to predict the missing tokens.
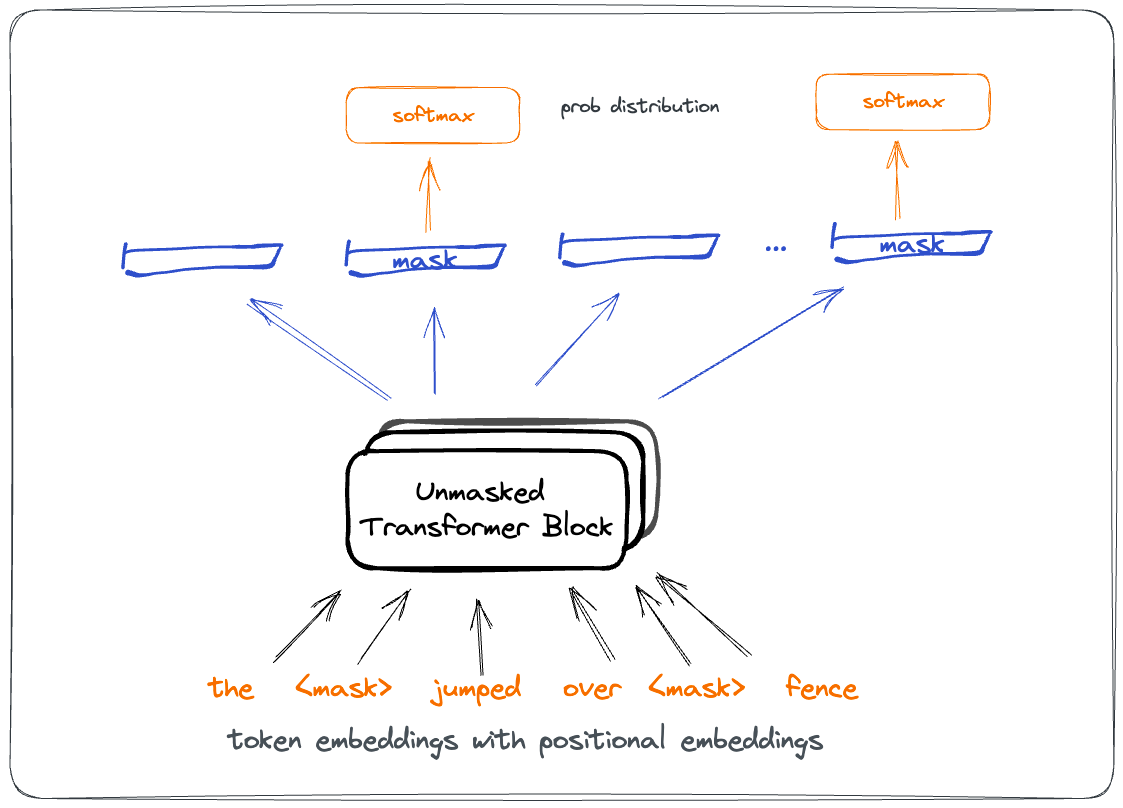
The layer before softmax represents pertained embeddings of the token. The stacked unmasked transformer allow encoding bidirectional context in representing the masked token embedding.
In order to use pretrained token embeddings we will typically fine-tune for a given task.
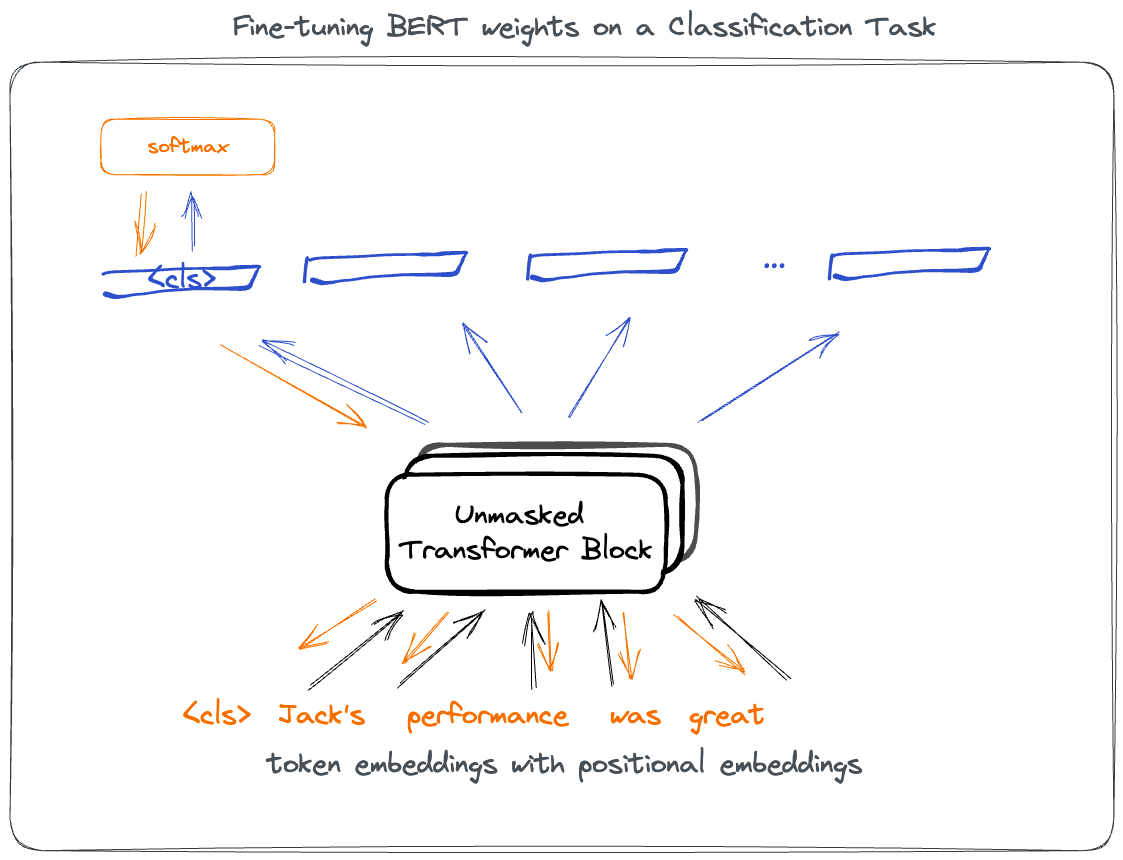
The trick here is to predict a CLS mask on the category label and allow back-prop to update weights across the entire network. Unlike ELMO, where weights were frozen.
Variants include:
* RoBERTa - bigger batches, no special treatment for CLS, more data (160GB), 500k steps (grad updates)
* XLnet - 900 tokens, transformer + recurrent
* ALBERT - shares parameters at layers
* DistilBERT - distill from larger model to smaller model
* tinyBERT - model distillation
BERT style of encoder transfomer architecture is great for pretraining objective. It can be further fine-tuned in specific way for classification, entailment, span classification. However it is not right for text-generation tasks. (question answering, translation, summarization, etc)
T4 Encoder-Decoder
Common Transformer Language Model Configurations:
-
Encoder Transformer
- Autoregressive encoder and non autoregressive decoder
- e.g. BERT
- Design: Stacked unmasked self-attention in encoder
- Train: word imputations (no directionality)
- Interesting as pre-trained token vectors, not for sequential token generation
- Useful for downstream tasks
-
Decoder Transformer (Transformer LM)
- Auto-regressive decoder
- e.g. OpenAi’s GPT series
- Design: Masked self attention stacked in decoder (no corresponding encoder)
- Train: next-word prediction with cross-entropy loss
- Useful for text-generation
-
Encoder-Decoder Transformer
- Encoder with autoregressive decoder
- e.g. Whisper Speech-to-Text, T5, or Machine Translation
- Design: Unmasked self attention encoder, masked decoder and cross-attention
- Useful in conditional sequence generation
-
Prefix LM (variant of decoder only)
- Design: Instead of encoder/decoder, its decoder-only, but source sequence is always unmasked
- Think of source sequence as context for target generation
- Useful for conditional sequence generation, and used in place of encoder-decoder problems
Picture reference: Yang et. al.
Engineering Transformers
While the model design seems elegant, the practical reality of getting these models to learn involves a lot of careful fine-tuning of the knobs (hyperparameters), engineering challenges to scale and parallelize, as well as introspection toolkits to interpret, debug, and iterate. By my estimates, far more FLOPs goes into getting the system right than the final-run which produces the model.
Here are some tricks to make transformer work:
- Adam optimizer, which customizes learning rate per parameters, is still in sufficient. People had success training the transformer with a specific learning rate schedule that first increases, then decreases the base learning rate.
- Label smoothing - a form of regularization. Plain MLE is too sure on some tokens, instead use KL divergence loss.
- Using neural architecture search to find architectural variants.
- Parallelization (model, and tensor paralleliztion). GPT3 is a 170 billion parameters model trained on 300B tokens. This requires solving some tought parallelization, data-transfer, and memory management problems to train on a thousands of GPUs.
Code Samples
Some code samples to get a better understanding of these ideas:
These repos are excellent references! It packs a great amount of detail in the small codebase. In order to scale this to large scale real-world scenarios, few more problems have to be solved.
For example, incremental data loaders, GPU parallelization in ways that can be distributed while minimizing data-movement, gpu data-bus latencies in the datacenter architecture, encoding scheme (the sample uses simple tokenizers), speeding up transformer block via factorization algorithms, mixed-precision numerical techniques to reduce memory footprint during gradient computations, and sometimes even numerical overflow issues.