What changed in AI?
2022 was a remarkable year for the field of Machine Learning AI as years of landmark research ideas culminated into applications with strong PMF. Image generation and dialog systems surpassed most of our expectations, shifting near-term upper-bound on coherence and reasoning abilities of these approaches. Products like Stable Diffusion, Midjourney, Dalle and ChatGPT are a result of tremendous engineering feat. They were simply careful and scaled-out application of known ideas.
Before 2022 the bottlenecks of modern AI architectures were quite clear:
- They required too much data relative our intuition of how little datapoints children need to learn a new idea. RL required too much data form simulations, making it suitable for games only.
- Most approaches lacked planning or long-term view beyond the immediate task, with the exception of RL-based policy learning.
- They lacked semantic coherence in language and image generation. We thought perhaps multiple modality of sensory information may be necessary to bring about semantic understanding. Without semantic understanding, for instance, applications like self-driving cars face a long-tail problem of configurations it can encounter.
- Instability in Generative approaches. While theoretically sound, GANs became unstable and were slow.
These limitations had raised a debate in the AI community whether we were on the right track with back-prop based representation learning as well as its autoregressive approaches. In 2022 that debate got settled, for now at least.
So, what changed? In my view there were two inflection points.
- First, OpenAI decided to push the boundary on autoregressive approach and see how far it could go. There was some evidence that LLMs had not yet plateaued with scale and this finding setup OpenAI for stronger bets.
- Second, ideas around Diffusion had matured quickly in 2021 to a level that it could make Image generation much faster and cheaper through parallel predictions.
An acceptable justification for scaling in my mind is this notion of “emergent behavior with scale”. It turns out the approach of error back-propagation, self-supervised and autoregressive learning, combined with long-term policy learning, does go a lot farther than I had thought.
It’s time to revisit the arc of progress and reevaluate technical bounds.
Backtracking AI
AI is nothing but an extension of computing. How we program these machines has always become more declarative over time. Starting from assembly, C, Java, and up to SQL, and now natural language prompts.
Removing control away from the programmer is both exciting and unnerving. We can now program circuitry that is just too complex for humans such as image recognition, voice recognition or having textual conversations. At the same time, the minimization of control sparks fear of AGI misalignment: AI machines behaving in ways we didn’t program or intend for them to.
The progress in machine learning has elevated the abstraction of automation to what humans were better than machines at: cognition, reasoning, and creativity.
The order of progress is roughly:
- Pattern recognition - statistical methods and early discriminative ML approaches: regression, tree, rule-based, CRFs, as well as generative models such as bayesian trees. These were good at finding patterns in structured data like sale data or ads click-prediction, but still felt mechanical. They needed a lot of careful tuning (programming) and weren’t good at doing things humans or animals do: see and hear.
- Cognition - Few trends converged to make System-1 level sense of image, sound, and textual information. It also led to an explosion of generative-ai usecases, especially with diffusion techniques that saw successes over GANs starting 2021.
a) Ideas around Convolution (CNNs) and deeper neural network architectures
b) Increase in computational power
c) Access to a lot more data (thanks to mobile)
d) Diffusion, ousting GANs for generative usecases. - Planning - Improvements in Reinforcement Learning, in particular Q-Learning, allowed us to build system with a longer-term objective. This led to successes in robotics as well as game-ai (alphago, alphazero). A big limitation of RL is that it still needs needs lot of datapoints, making it ideal for gaming (as it can be simulated), but less for IRL usecases.
- Semantic Reasoning and Memory - We are now at a point where we can see signs of deeper semantic understanding and reasoning abilities. It was made possible due to:
a) The transformer architecture, which scaled better to capture context and superseded Recurrent Neural Network architectures.
Aside: Why was transformer architecture, which can be seen as learning dimensionality reduction, so impactful when we had Kernel methods for decades? (this discussion deserves a full post on its own)
b) Scale-up of computational power and techniques to scale to bigger models.
Aside: We often use parameters to measure model size, but FLOPs is of equal importance and captures raw horsepower better. Parameters cover token vocabulary coming from larger datasets as well as architecture of NN, and lot of interesting attempts (e.g. Chinchilla and Llama) to show that lower parameter size with more data can perform equally well. The uber point is still that we scaled to bigger models needing more compute.
The idea of Emergent Behavior
I found this research on emergent-behaviors quite fascinating.
We used to see linear improvements with scale (of data, parameters/architecture, training epochs) against benchmark tasks. But what we are finding across multiple large scale models is that there is an inflection point at which the accuracy curve improves significantly and our earlier extrapolations for LLM’s abilities don’t apply.
I suspect this inflection point is evidence of a true learned behavior, going from quantitative statistical patterns, to deriving meaningful abstractions.
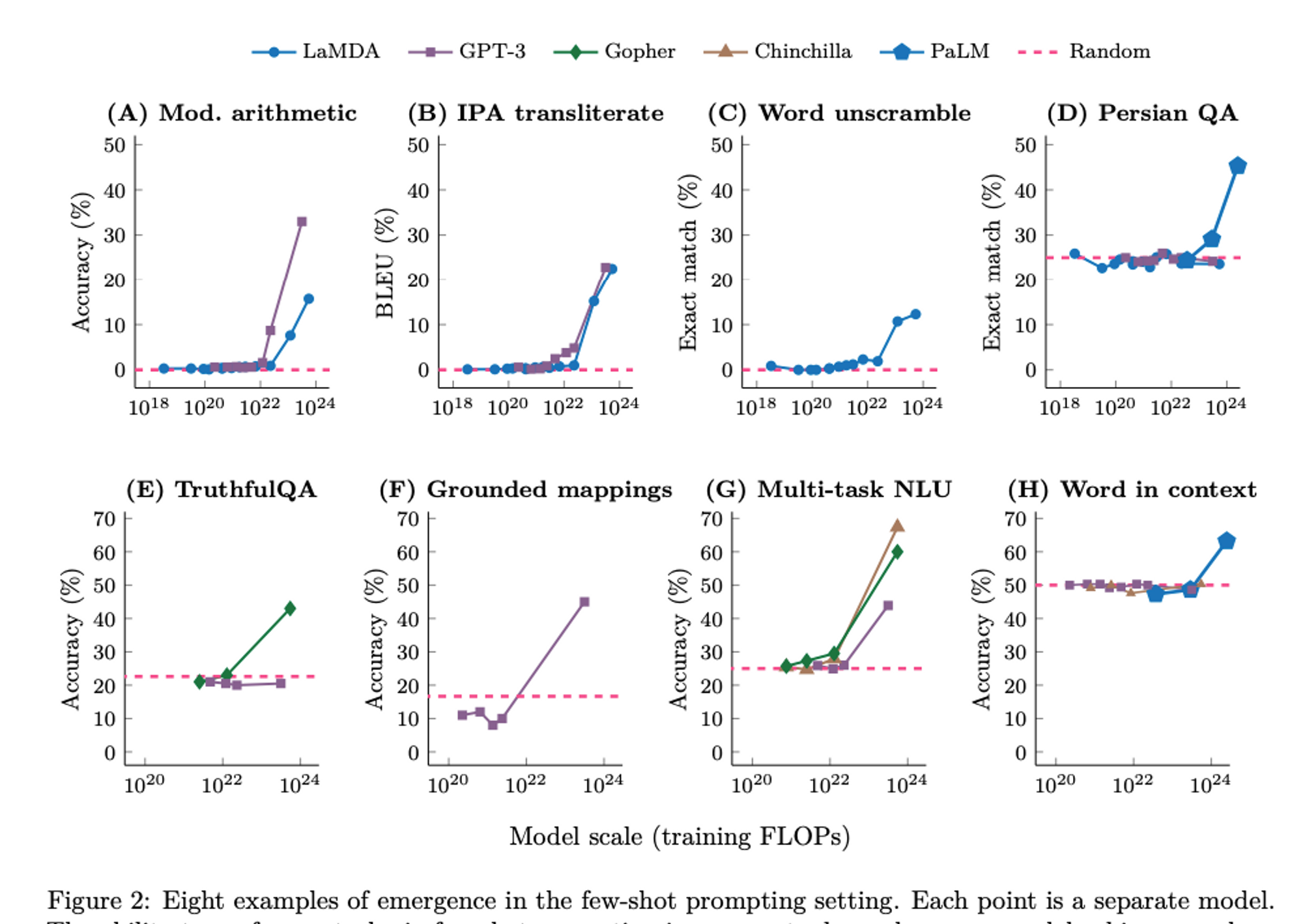
What is more exciting, these unpredictable outcomes with scale makes us question how much more can the LLMs learn with our existing approaches. Perhaps they can achieve human-level or better performance at an array of new capabilities.
It is possible similar emergence will be seen in other modalities of learning, for instance around image, video, and sound.
Is AI the next epoch of technology?
For decades AI and ML have had a strong impact on tech platforms. From content recommendations, search, ride-sharing, to safety and integrity, all use ML at its core, but its applications were limited to predictive abilities within large tech platforms.
We can now see a path from these predictive usecases to generative usecases, making machines do what humans were uniquely better at: cognition, reasoning, and creativity, and in the process, opening up the power of large-scale AI to rest of the world.
In my mental model, a substantially new and advanced technology gets deployed to market in two phases. Phase 1 is rather straightforward and empowers user’s existing behaviors. Where as Phase 2 is unpredictabe, and creates new behaviors (lets say emergent behaviors :D) that we can not today rationalize.
While this phase creates completely new businesses (e.g. app store), it is also disruptive to an incumbent industry’s business models. Prior cycles around www and mobile went through similar phases. As a result, dollars ended up shifting from a traditional industries who were sitting rigidly in their business models, to their tech disruptor counterpart. This happened with media, retail, transportation etc.
Phase 1
AI for now seems to be at the cusp of Phase 1. An important realization is that phase 1 makes existing powers stronger. My prediction is that Google, Meta, Microsoft will become stronger as a result of magical capabilities of large scale AI, further strengthening their monopolies and increasing pricing power in years to come.
Why is that when everyone now has access to OpenAI and Stabiliy AI?
There seems to be a clear strategy at play around commoditizing your complement (Joel’s original post) by Meta, Google/DeepMind, and perhaps more. So, one could presume safely that access to reasonable AI will be commoditized.
As a result, it is not access to AI tech that is going to be a moat, it is access to data. Google, meta, etc simply have a lot of interesting and useful data. On the application side, Notion, Intercom, Khan academy, canva, etc have been quick to integrate AI assistants, and as they fine-tune and improve their applications of AI, it simply gives them power over a competitive startup challenging them in their respective space.
Phase 2
Phase 2 is harder to predict. My naïve guess at the moment is that entertainment industry is going to face a major disruption in the next decade, and Hollywood’s dollars are going to start flowing into tech. This is the real next epoch of tech.
Just as 2022 was a surprising and groundbreaking year, it is possible a lot more foundational innovation is yet to come, further accelerating (or disrupting) AI’s impact on society.
Regardless of the specific path AI tech takes, one thing seems clear: the arc of computing has a lot more horsepower left to push the frontier of efficiency in our society.